Podar folhas desnecessárias no sklearn DecisionTreeClassifier
Uso sklearn.tree.DecisionTreeClassifier para criar uma árvore de decisão. Com as configurações ideais de parâmetros, recebo uma árvore com folhas desnecessárias (consulteexemplo figura abaixo - Não preciso de probabilidades, portanto, os nós das folhas marcados em vermelho são uma divisão desnecessária)
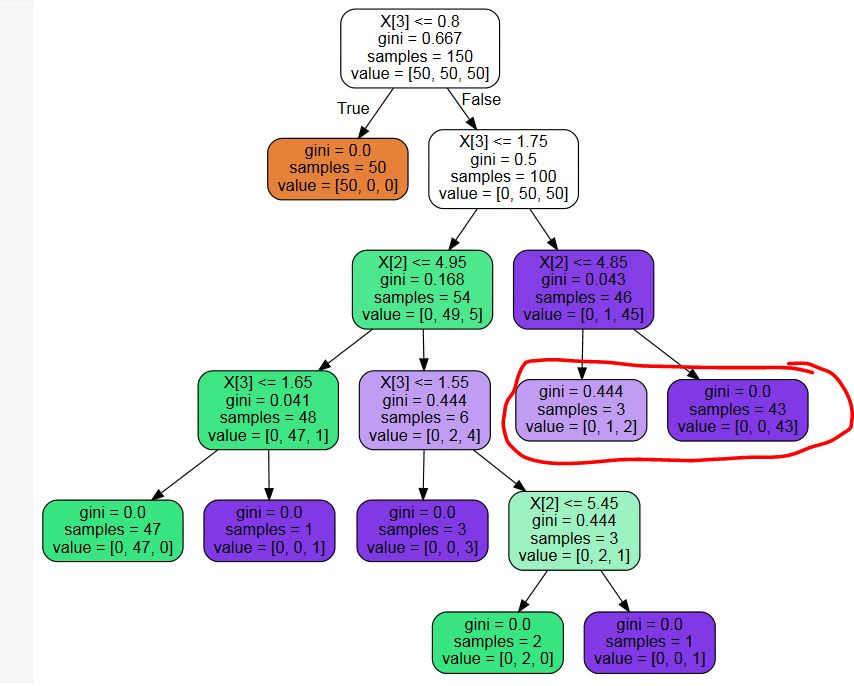
Existe alguma biblioteca de terceiros para remover esses nós desnecessários? Ou um trecho de código? Eu poderia escrever um, mas não consigo imaginar que sou a primeira pessoa com esse problema ...
Código para replicar:
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
mdl = DecisionTreeClassifier(max_leaf_nodes=8)
mdl.fit(X,y)
PS: Tentei várias pesquisas de palavras-chave e fico surpreso por não encontrar nada - não há realmente nenhuma poda em geral no sklearn?
PPS: Em resposta à possível duplicata: Enquantoa pergunta sugerida pode me ajudar ao codificar o algoritmo de poda, ele responde a uma pergunta diferente - quero me livrar das folhas que não alteram a decisão final, enquanto a outra pergunta quer um limite mínimo para a divisão de nós.
PPPS: A árvore mostrada é um exemplo para mostrar meu problema. Estou ciente do fato de que as configurações de parâmetro para criar a árvore são abaixo do ideal. Não estou perguntando sobre como otimizar essa árvore específica, preciso fazer uma poda para se livrar das folhas que podem ser úteis se alguém precisar de probabilidades de classe, mas não são úteis se estiver interessado apenas na classe mais provável.