Это просто воспроизводимый пример, предназначенный для демонстрации моей проблемы и, очевидно, не моего реального кода ... Я знаю о различных настройках дерева решений, тем не менее, в sklearn на данный момент просто отсутствуют какие-либо опции после сокращения.
ользую sklearn.tree.DecisionTreeClassifier для построения дерева решений. При оптимальных настройках параметров я получаю дерево с ненужными листьями (см.пример рисунок ниже - мне не нужны вероятности, поэтому листовые узлы, отмеченные красным, являются ненужным разделением)
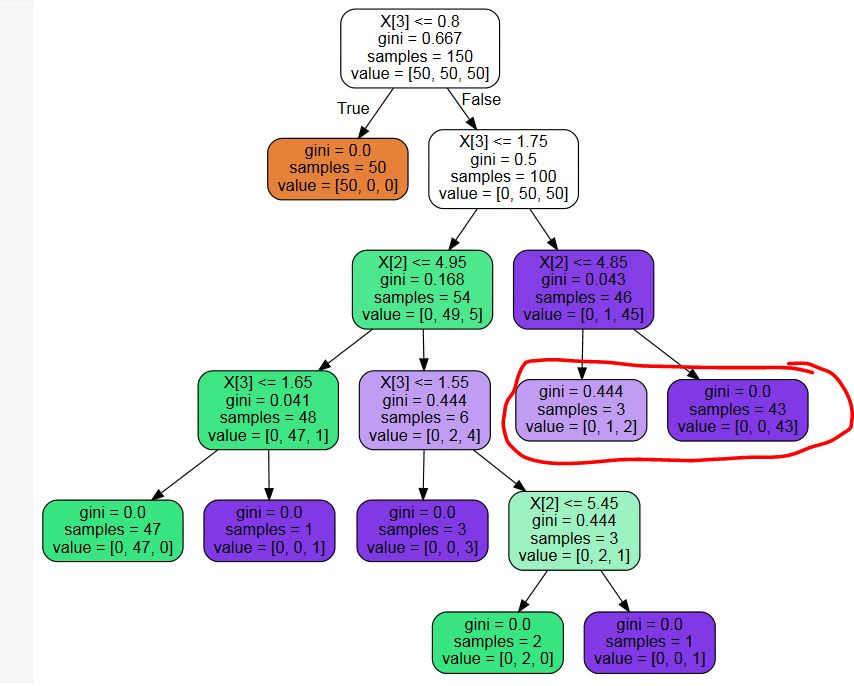
Есть какая-нибудь сторонняя библиотека для обрезки этих ненужных узлов? Или фрагмент кода? Я мог бы написать один, но я не могу себе представить, что я первый человек с этой проблемой ...
Код для тиражирования:
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
mdl = DecisionTreeClassifier(max_leaf_nodes=8)
mdl.fit(X,y)
PS: я пробовал многократный поиск по ключевым словам и удивляюсь, что ничего не нашёл - разве в sklearn вообще нет постобрезки вообще?
PPS: в ответ на возможный дубликат: покапредложенный вопрос может помочь мне при написании самого алгоритма сокращения, он отвечает на другой вопрос - я хочу избавиться от листьев, которые не меняют окончательного решения, в то время как другой вопрос требует минимального порога для разделения узлов.
PPPS: Показанное дерево является примером, показывающим мою проблему. Мне известно о том, что настройки параметров для создания дерева являются неоптимальными. Я не спрашиваю об оптимизации этого конкретного дерева, мне нужно сделать пост-обрезку, чтобы избавиться от листьев, которые могут быть полезны, если нужны классовые вероятности, но бесполезны, если интересуются только наиболее вероятным классом.