Как преобразовать изображение в символьные сегменты?
Часто в процессе распознавания файл изображения по существу разрезается на сегменты, и каждый символ распознается как сегмент каждого.
Например,
должен быть преобразован в нечто подобное
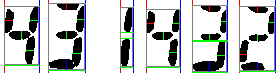
Кроме того, есть ли алгоритм для азиатских языков, таких как телугу, легко доступных для этой цели? Если нет, то как это делается для английского языка?