Como encontrar a frequência ngram de uma coluna em um dataframe de pandas?
Abaixo está o quadro de dados de entrada dos pandas que tenho.
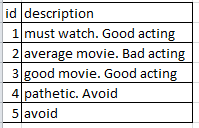
Quero encontrar a frequência de unigramas e bigrams. Uma amostra do que eu estou esperando é mostrada abaixo
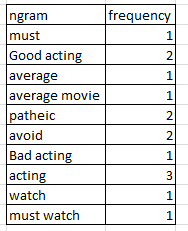
Como fazer isso usando o nltk ou o scikit learn?
Eu escrevi o código abaixo que usa uma string como entrada. Como estendê-lo para series / dataframe?
from nltk.collocations import *
desc='john is a guy person you him guy person you him'
tokens = nltk.word_tokenize(desc)
bigram_measures = nltk.collocations.BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(tokens)
finder.ngram_fd.viewitems()