Как найти ngram частоту столбца в кадре данных панд?
Ниже приведен входной кадр данных, который у меня есть.
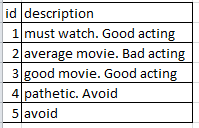
Я хочу найти частоту униграмм и биграмм. Пример того, что я ожидаю, показан ниже.
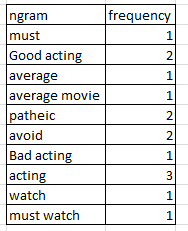
Как это сделать с помощью nltk или scikit learn?
Я написал код ниже, который принимает строку в качестве ввода. Как расширить его до серии / dataframe?
from nltk.collocations import *
desc='john is a guy person you him guy person you him'
tokens = nltk.word_tokenize(desc)
bigram_measures = nltk.collocations.BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(tokens)
finder.ngram_fd.viewitems()