¿Cómo encontrar la frecuencia de ngram de una columna en un marco de datos de pandas?
A continuación se muestra el marco de datos de pandas de entrada que tengo.
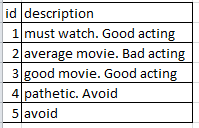
Quiero encontrar la frecuencia de unigramas y bigramas. A continuación se muestra una muestra de lo que estoy esperando.
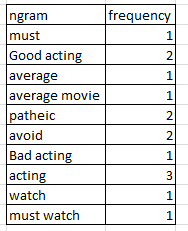
¿Cómo hacer esto usando nltk o scikit learn?
Escribí el siguiente código que toma una cadena como entrada. ¿Cómo extenderlo a series / dataframe?
from nltk.collocations import *
desc='john is a guy person you him guy person you him'
tokens = nltk.word_tokenize(desc)
bigram_measures = nltk.collocations.BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(tokens)
finder.ngram_fd.viewitems()