Perf superando o simples loop ligado à CPU: trabalho misterioso do kernel?
Eu tenho usado o Linuxperf por algum tempo para fazer o perfil do aplicativo. Geralmente, o aplicativo com perfil é bastante complexo, portanto, tende-se a simplesmente levar os valores dos contadores relatados pelo valor nominal, desde que não haja nenhumBruto discrepância com o que você pode esperar com base nos primeiros princípios.
Recentemente, no entanto, criei um perfil de alguns programas triviais de montagem de 64 bits - triival o suficiente para que se possa calcular quase exatamente o valor esperado de vários contadores, e parece queperf stat está contando demais.
Pegue o seguinte loop, por exemplo:
.loop:
nop
dec rax
nop
jne .loop
Isso simplesmente fará um loopn vezes, onden é o valor inicial derax. Cada iteração do loop executa 4 instruções, então você esperaria4 * n instruções executadas, além de uma pequena sobrecarga fixa para inicialização e finalização do processo e o pequeno pedaço de código que definen antes de entrar no loop.
Aqui está o (típico)perf stat saída paran = 1,000,000,000:
~/dev/perf-test$ perf stat ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
301.795151 task-clock (msec) # 0.998 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.007 K/sec
1,003,144,430 cycles # 3.324 GHz
4,000,410,032 instructions # 3.99 insns per cycle
1,000,071,277 branches # 3313.742 M/sec
1,649 branch-misses # 0.00% of all branches
0.302318532 seconds time elapsed
Hã. Em vez de cerca de 4.000.000.000 de instruções e 1.000.000.000 de ramificações, vemos 410.032 instruções extras misteriosas e 71.277 ramificações. Sempre há instruções "extras", mas a quantidade varia um pouco - as execuções subsequentes, por exemplo, tiveram 421K, 563K e 464Kextra instruções, respectivamente. Você pode executar isso sozinho em seu sistema criando meuprojeto github simples.
OK, então você pode imaginar que essas poucas centenas de milhares de instruções extras são apenas custos fixos de configuração e desmontagem de aplicativos (a configuração da terra do usuário émuito pequeno, mas pode haver coisas ocultas). Vamos tentarn=10 billion então:
~/dev/perf-test$ perf stat ./perf-test-nop 10
Performance counter stats for './perf-test-nop 10':
2907.748482 task-clock (msec) # 1.000 CPUs utilized
3 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.001 K/sec
10,012,820,060 cycles # 3.443 GHz
40,004,878,385 instructions # 4.00 insns per cycle
10,001,036,040 branches # 3439.443 M/sec
4,960 branch-misses # 0.00% of all branches
2.908176097 seconds time elapsed
Agora existem ~ 4,9 milhõesextra instruções, cerca de um aumento de 10x antes, proporcional ao aumento de 10x na contagem de loop.
Você pode tentar vários contadores - todos os relacionados à CPU mostram aumentos proporcionais semelhantes. Vamos nos concentrar na contagem de instruções para manter as coisas simples. Usando o:u e:k sufixos para medirdo utilizador enúcleo respectivamente, mostra que as contagens incorridas nonúcleo são responsáveis por quase todos os eventos extras:
~/dev/perf-test$ perf stat -e instructions:u,instructions:k ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
4,000,000,092 instructions:u
388,958 instructions:k
0.301323626 seconds time elapsed
Bingo. Das 389.050 instruções extras, 99,98% delas (388.958) foram incorridas no kernel.
OK, mas onde isso nos deixa? Este é um loop vinculado à CPU trivial. Ele não faz nenhuma chamada do sistema e não acessa a memória (que pode indiretamente invocar o kernel através do mecanismo de falha de página). Por que o kernel está executando instruções em nome do meu aplicativo?
Não parece ser causado por alternâncias de contexto ou migrações de CPU, pois são iguais ou próximas a zero e, em qualquer caso, oextra a contagem de instruções não se correlaciona com as execuções onde mais desses eventos ocorreram.
O número de instruções extras do kernel é de fato muito suave com a contagem de loops. Aqui está um gráfico de (bilhões de) iterações de loop versus instruções do kernel:
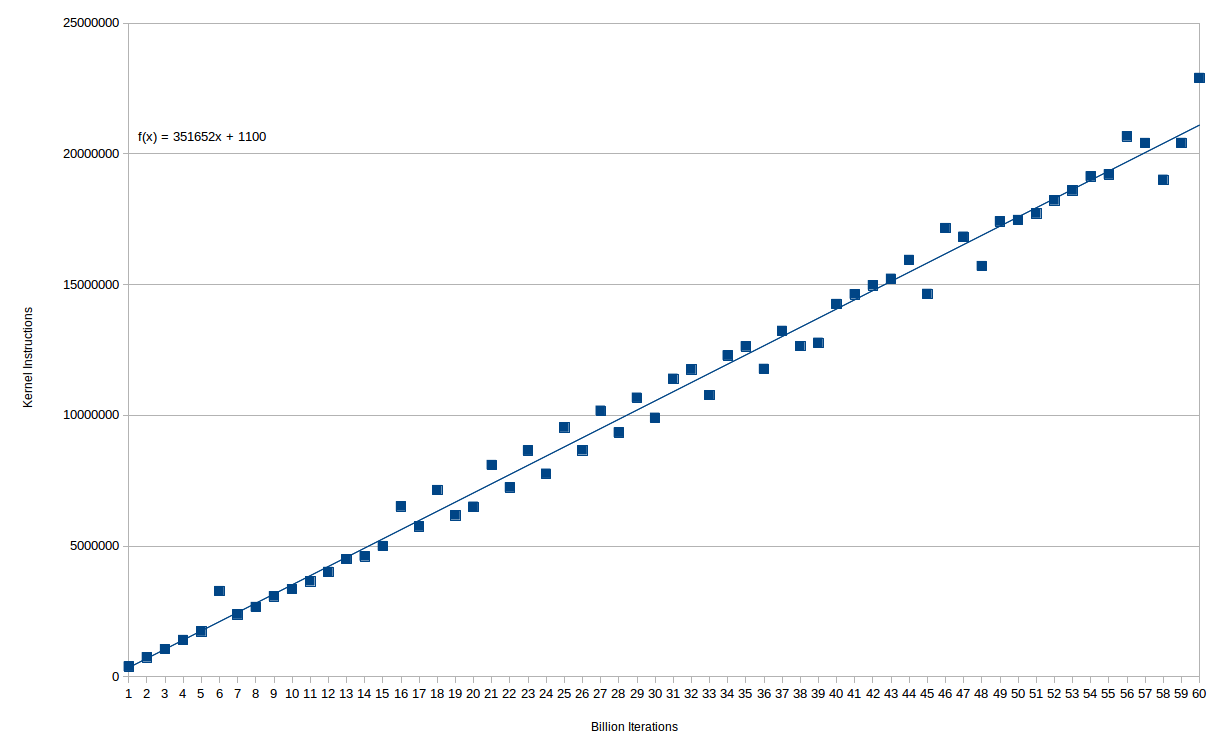
Você pode ver que o relacionamento é praticamente perfeitamente linear - na verdade, até 15 e 9 iterações, há apenas um erro. Depois disso, parece haver duas linhas separadas, sugerindo algum tipo de quantização do que quer que cause o excesso de tempo. Em qualquer caso, você incorre em cerca de 350K de instruções do kernel para todas as instruções 1e9 executadas no loop principal.
Finalmente, observei que o número de instruções do kernel executadas parece proporcional ao$44perf45$programa semelhante, mas com um dosnop instruções substituídas poridiv que tem uma latência de cerca de 40 ciclos (algumas linhas desinteressantes removidas):
~/dev/perf-test$ perf stat ./perf-test-div 10
Performance counter stats for './perf-test-div 10':
41,768,314,396 cycles # 3.430 GHz
4,014,826,989 instructions # 0.10 insns per cycle
1,002,957,543 branches # 82.369 M/sec
12.177372636 seconds time elapsed
Aqui fizemos ~ 42e9 ciclos para concluir as iterações 1e9 e tínhamos ~ 14.800.000 instruções extras. Isso se compara a apenas ~ 400.000 instruções extras para os mesmos loops 1e9 comnop. Se compararmos com onop loop que leva aproximadamente o mesmo número decycles (Iterações 40e9), vemos quase exatamente o mesmo número de instruções extras:
~/dev/perf-test$ perf stat ./perf-test-nop 41
Performance counter stats for './perf-test-nop 41':
41,145,332,629 cycles # 3.425
164,013,912,324 instructions # 3.99 insns per cycle
41,002,424,948 branches # 3412.968 M/sec
12.013355313 seconds time elapsed
O que há com este trabalho misterioso acontecendo no kernel?
1 Aqui, estou usando os termos "tempo" e "ciclos" de forma mais ou menos intercambiável aqui. A CPU funciona durante esses testes, portanto, alguns efeitos térmicos relacionados ao turbocompressor são modificados diretamente para o tempo.