Recuento excesivo del rendimiento del bucle simple vinculado a la CPU: ¿trabajo misterioso del núcleo?
He estado usando Linuxperf durante algún tiempo para hacer perfiles de aplicaciones. Por lo general, la aplicación perfilada es bastante compleja, por lo que uno tiende a tomar simplemente los valores de contador informados a su valor nominal, siempre que no haya ningunobruto discrepancia con lo que puede esperar basado en los primeros principios.
Sin embargo, recientemente he perfilado algunos programas triviales de ensamblaje de 64 bits, lo suficientemente trivial como para poder calcular casi exactamente el valor esperado de varios contadores, y parece queperf stat está contando en exceso.
Tome el siguiente ciclo, por ejemplo:
.loop:
nop
dec rax
nop
jne .loop
Esto simplemente se repetirán veces, donden es el valor inicial derax. Cada iteración del bucle ejecuta 4 instrucciones, por lo que esperaría4 * n instrucciones ejecutadas, más una pequeña sobrecarga fija para el inicio y finalización del proceso y el pequeño fragmento de código que establecen antes de entrar en el bucle.
Aquí está el (típico)perf stat salida paran = 1,000,000,000:
~/dev/perf-test$ perf stat ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
301.795151 task-clock (msec) # 0.998 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.007 K/sec
1,003,144,430 cycles # 3.324 GHz
4,000,410,032 instructions # 3.99 insns per cycle
1,000,071,277 branches # 3313.742 M/sec
1,649 branch-misses # 0.00% of all branches
0.302318532 seconds time elapsed
Huh En lugar de unas 4,000,000,000 de instrucciones y 1,000,000,000 de sucursales, vemos un misterioso 410,032 instrucciones extra y 71,277 sucursales. Siempre hay instrucciones "adicionales", pero la cantidad varía un poco: las ejecuciones posteriores, por ejemplo, tuvieron 421K, 563K y 464Kextra instrucciones, respectivamente. Puede ejecutar esto usted mismo en su sistema construyendo miproyecto simple github.
De acuerdo, puede adivinar que estos cientos de miles de instrucciones adicionales son solo costos fijos de configuración de la aplicación y desmontaje (la configuración del usuario esmuy pequeña, pero puede haber cosas ocultas). Probemos porn=10 billion entonces:
~/dev/perf-test$ perf stat ./perf-test-nop 10
Performance counter stats for './perf-test-nop 10':
2907.748482 task-clock (msec) # 1.000 CPUs utilized
3 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.001 K/sec
10,012,820,060 cycles # 3.443 GHz
40,004,878,385 instructions # 4.00 insns per cycle
10,001,036,040 branches # 3439.443 M/sec
4,960 branch-misses # 0.00% of all branches
2.908176097 seconds time elapsed
Ahora hay ~ 4.9 millonesextra instrucciones, aproximadamente un aumento de 10 veces respecto al anterior, proporcional al aumento de 10 veces en el recuento del bucle.
Puede probar varios contadores: todos los relacionados con la CPU muestran aumentos proporcionales similares. Centrémonos entonces en el recuento de instrucciones para mantener las cosas simples. Utilizando la:u y:k sufijos a medidausuario ynúcleo recuentos, respectivamente, muestra que los recuentos incurridos en elnúcleo representan casi todos los eventos adicionales:
~/dev/perf-test$ perf stat -e instructions:u,instructions:k ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
4,000,000,092 instructions:u
388,958 instructions:k
0.301323626 seconds time elapsed
Bingo. De las 389,050 instrucciones adicionales, el 99,98% de ellas (388,958) se incurrieron en el núcleo.
Bien, pero ¿dónde nos deja eso? Este es un bucle trivial vinculado a la CPU. No realiza ninguna llamada al sistema y no accede a la memoria (que puede invocar indirectamente el núcleo a través del mecanismo de falla de página). ¿Por qué el núcleo ejecuta instrucciones en nombre de mi aplicación?
No parece ser causado por cambios de contexto o migraciones de CPU, ya que estos están en o cerca de cero, y en cualquier caso elextra el recuento de instrucciones no se correlaciona con las ejecuciones donde ocurrieron más de esos eventos
El número de instrucciones adicionales del núcleo es, de hecho, muy suave con el recuento de bucles. Aquí hay un gráfico de (miles de millones de) iteraciones de bucle versus instrucciones del núcleo:
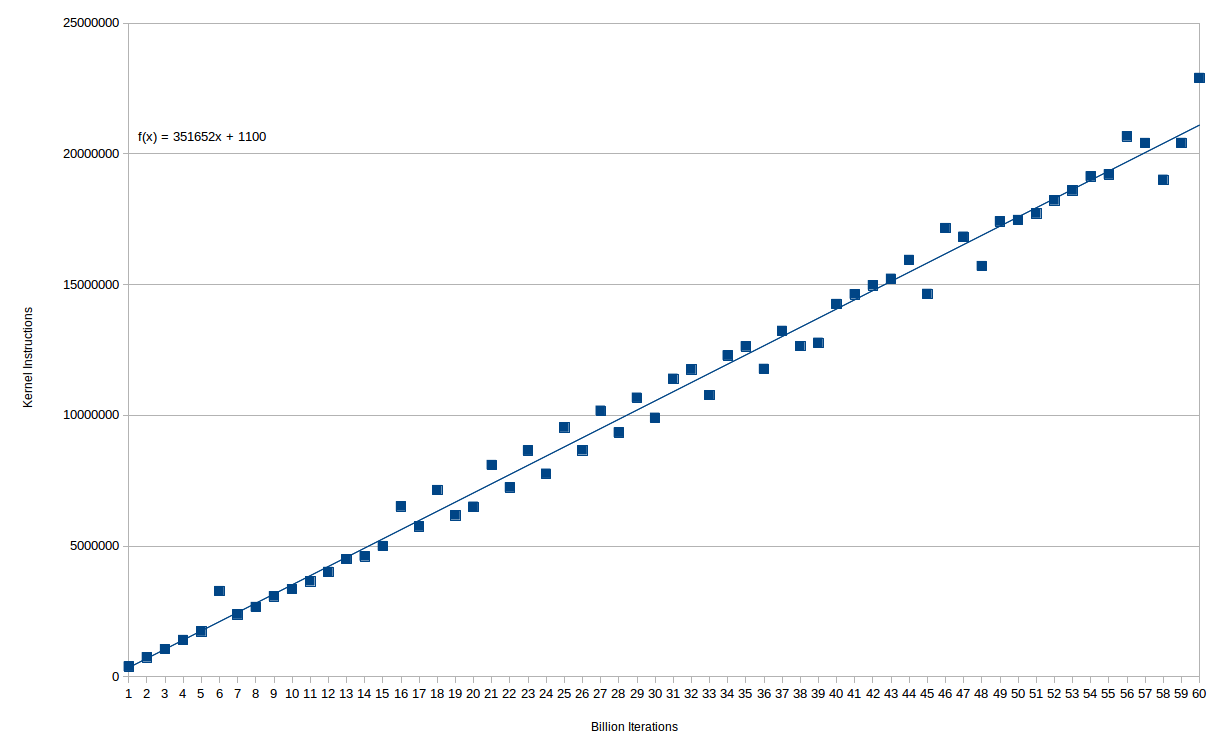
Puede ver que la relación es bastante lineal: de hecho, hasta 15e9 iteraciones solo hay un valor atípico. Después de eso, parece haber dos líneas separadas, lo que sugiere algún tipo de cuantización de lo que sea que cause el exceso de tiempo. En cualquier caso, incurre en unas 350K instrucciones del núcleo por cada 1e9 instrucciones ejecutadas en el bucle principal.
Finalmente, noté que el número de instrucciones del núcleo ejecutadas parece proporcional a$44perf45$programa similar, pero con uno de losnop instrucciones reemplazadas por unidiv que tiene una latencia de alrededor de 40 ciclos (se eliminaron algunas líneas poco interesantes):
~/dev/perf-test$ perf stat ./perf-test-div 10
Performance counter stats for './perf-test-div 10':
41,768,314,396 cycles # 3.430 GHz
4,014,826,989 instructions # 0.10 insns per cycle
1,002,957,543 branches # 82.369 M/sec
12.177372636 seconds time elapsed
Aquí tomamos ~ 42e9 ciclos para completar 1e9 iteraciones, y tuvimos ~ 14,800,000 instrucciones adicionales. Eso se compara con solo ~ 400,000 instrucciones adicionales para los mismos bucles 1e9 connop. Si comparamos con elnop bucle que toma aproximadamente el mismo número decycles (40e9 iteraciones), vemos casi exactamente el mismo número de instrucciones adicionales:
~/dev/perf-test$ perf stat ./perf-test-nop 41
Performance counter stats for './perf-test-nop 41':
41,145,332,629 cycles # 3.425
164,013,912,324 instructions # 3.99 insns per cycle
41,002,424,948 branches # 3412.968 M/sec
12.013355313 seconds time elapsed
¿Qué pasa con este misterioso trabajo que ocurre en el núcleo?
1 Aquí estoy usando los términos "tiempo" y "ciclos" más o menos intercambiables aquí. La CPU se ejecuta completamente durante estas pruebas, por lo que, a pesar de algunos efectos térmicos relacionados con el turboalimentador, los ciclos son directamente proporcionales al tiempo.