Perf пересчет простого цикла с привязкой к процессору: загадочная работа ядра?
Я использую Linuxперфорация в течение некоторого времени, чтобы сделать профилирование приложения. Обычно профилированное приложение является довольно сложным, поэтому обычно просто принимают значения счетчика, указанные в отчете, по номиналу, если их нет.валовой расхождение с тем, что вы могли бы ожидать на основе первых принципов.
Однако недавно я профилировал некоторые тривиальные 64-битные программы сборки - достаточно триалиально, чтобы можно было почти точно рассчитать ожидаемое значение различных счетчиков, и кажется, чтоperf stat это пересчет.
Возьмите следующий цикл, например:
.loop:
nop
dec rax
nop
jne .loop
Это будет просто петляn раз, гдеn является начальным значениемrax, Каждая итерация цикла выполняет 4 инструкции, так что вы ожидаете4 * n выполненные инструкции, плюс небольшие фиксированные накладные расходы на запуск и завершение процесса и небольшой кусочек кода, который устанавливаетn перед входом в цикл.
Вот (типичный)perf stat выход дляn = 1,000,000,000:
~/dev/perf-test$ perf stat ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
301.795151 task-clock (msec) # 0.998 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.007 K/sec
1,003,144,430 cycles # 3.324 GHz
4,000,410,032 instructions # 3.99 insns per cycle
1,000,071,277 branches # 3313.742 M/sec
1,649 branch-misses # 0.00% of all branches
0.302318532 seconds time elapsed
Да. Вместо 4 000 000 000 инструкций и 1 000 000 000 ветвей мы видим загадочные дополнительные 4 0 032 инструкции и 71 277 ветвей. Всегда есть «лишние» инструкции, но их количество немного меняется - например, последующие запуски имели 421К, 563К и 464Кдополнительный инструкции соответственно. Вы можете запустить это самостоятельно в своей системе, построив мойпростой проект GitHub.
Хорошо, так что вы можете догадаться, что эти несколько сотен тысяч дополнительных инструкций являются просто фиксированными затратами на установку приложения и демонтаж (пользовательские настройкиочень маленький, но там могут быть скрытые вещи). Давай попробуем дляn=10 billion затем:
~/dev/perf-test$ perf stat ./perf-test-nop 10
Performance counter stats for './perf-test-nop 10':
2907.748482 task-clock (msec) # 1.000 CPUs utilized
3 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.001 K/sec
10,012,820,060 cycles # 3.443 GHz
40,004,878,385 instructions # 4.00 insns per cycle
10,001,036,040 branches # 3439.443 M/sec
4,960 branch-misses # 0.00% of all branches
2.908176097 seconds time elapsed
Сейчас там ~ 4,9 миллионадополнительный инструкции, примерно в 10 раз больше, чем раньше, пропорционально увеличению числа циклов в 10 раз.
Вы можете попробовать различные счетчики - все связанные с CPU показывают одинаковые пропорциональные увеличения. Давайте сосредоточимся на подсчете команд, чтобы все было просто. С использованием:u а также:k суффиксы для измеренияпользователь а такжеядро подсчет, соответственно, показывает, что подсчет произведен вядро учитывать почти все дополнительные события:
~/dev/perf-test$ perf stat -e instructions:u,instructions:k ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
4,000,000,092 instructions:u
388,958 instructions:k
0.301323626 seconds time elapsed
Бинго. Из 389 050 дополнительных инструкций полностью 99,98% из них (388 958) были получены в ядре.
Хорошо, но где это нас покидает? Это тривиальный цикл, связанный с процессором. Он не выполняет никаких системных вызовов и не обращается к памяти (что может косвенно вызывать ядро через механизм сбоя страницы). Почему ядро выполняет инструкции от имени моего приложения?
Кажется, это не вызвано переключением контекста или миграцией процессора, так как они равны нулю или близки к нему, и в любом случаедополнительный количество команд не коррелирует с запусками, в которых произошло больше таких событий.
Количество дополнительных инструкций ядра на самом деле очень гладкое с количеством циклов. Вот диаграмма (миллиарды) итераций цикла в сравнении с инструкциями ядра:
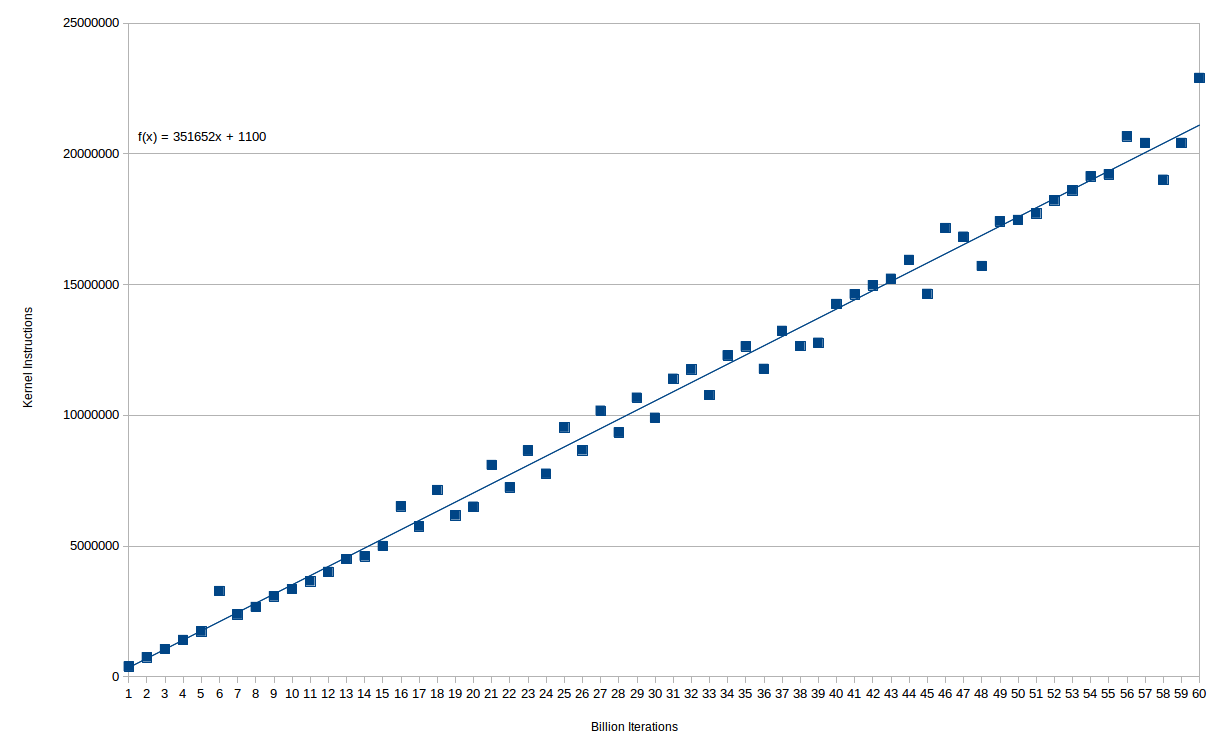
Вы можете видеть, что отношения в значительной степени идеально линейны - фактически, до 15e9 итераций есть только один выброс. После этого, кажется, есть две отдельные строки, предполагающие некоторое квантование того, что вызывает избыточное время. В любом случае вы получаете около 350K инструкций ядра для каждых 1e9 инструкций, выполняемых в основном цикле.
Наконец, я заметил, что количество выполненных инструкций ядра кажется пропорциональнымвремя выполнения1 (или процессорное время), а не выполненные инструкции. Чтобы проверить это, я используюаналогичная программа, но с одним изnop инструкции заменены наidiv с задержкой около 40 циклов (удалены некоторые неинтересные строки):
~/dev/perf-test$ perf stat ./perf-test-div 10
Performance counter stats for './perf-test-div 10':
41,768,314,396 cycles # 3.430 GHz
4,014,826,989 instructions # 0.10 insns per cycle
1,002,957,543 branches # 82.369 M/sec
12.177372636 seconds time elapsed
Здесь мы взяли ~ 42e9 циклов, чтобы выполнить 1e9 итераций, и у нас было ~ 14 800 000 дополнительных инструкций. Это сопоставимо только с ~ 400 000 дополнительных инструкций для тех же циклов 1e9 сnop, Если мы сравним сnop цикл, который занимает примерно столько жеcycles (40e9 итераций), мы видим почти такое же количество дополнительных инструкций:
~/dev/perf-test$ perf stat ./perf-test-nop 41
Performance counter stats for './perf-test-nop 41':
41,145,332,629 cycles # 3.425
164,013,912,324 instructions # 3.99 insns per cycle
41,002,424,948 branches # 3412.968 M/sec
12.013355313 seconds time elapsed
Что за таинственная работа, происходящая в ядре?
1 Здесь я использую термины «время» и «циклы» более или менее взаимозаменяемо здесь. Во время этих тестов процессор не работает, поэтому по модулю некоторых тепловых эффектов, связанных с турбонаддувом, циклы прямо пропорциональны времени.