Ejecute análisis de regresión en múltiples subconjuntos de columnas de pandas de manera eficiente
Podría haber optado por una pregunta más corta que solo se centra en el problema central aquí que eslista de permutaciones. Pero la razón por la que traigostatsmodels ypandas La pregunta es que pueden existir herramientas específicas para la regresión gradual que, al mismo tiempo, tiene la flexibilidad de almacenar la salida de regresión deseada como voy a mostrar a continuación, pero que son mucho más eficientes. Por lo menos eso espero.
Dado un marco de datos como el siguiente:
Fragmento de código 1:
# Imports
import pandas as pd
import numpy as np
import itertools
import statsmodels.api as sm
# A datafrane with random numbers
np.random.seed(123)
rows = 12
listVars= ['y','x1', 'x2', 'x3']
rng = pd.date_range('1/1/2017', periods=rows, freq='D')
df_1 = pd.DataFrame(np.random.randint(100,150,size=(rows, len(listVars))), columns=listVars)
df_1 = df_1.set_index(rng)
print(df_1)
Captura de pantalla 1:

Me gustaría ejecutar varios análisis de regresión en la variable dependiente y utilizando múltiples combinaciones de las variables independientes x1, x2 y x3. En otras palabras, este es un análisis de regresión paso a paso donde y se prueba contra x1, y luego x2 y x3 consecutivamente. Entonces y se prueba con el conjunto de x1 Y x2, y así sucesivamente:
['y', ['x1']]['y', ['x2']]['y', ['x3']]['y', ['x1', 'x2']]['y', ['x1', 'x2', 'x3']]Mi enfoque ineficiente:
En los dos primeros fragmentos a continuación, puedo hacer exactamente esto codificando la secuencia de ejecución usando una lista de listas.
Aquí están los subconjuntos de listVars:
Fragmento de código 2:
listExec = [[listVars[0], listVars[1:2]],
[listVars[0], listVars[2:3]],
[listVars[0], listVars[3:4]],
[listVars[0], listVars[1:3]],
[listVars[0], listVars[1:4]]]
for l in listExec:
print(l)
Captura de pantalla 2:

Con listExec puedo configurar un procedimiento para el análisis de regresión y obtener almacenar un montón de resultados (rsquared o el modo de salida del modelo completo.summary ()) en una lista como esta:
Fragmento de código 3:
allResults = []
for l in listExec:
x = listVars[1]
x = sm.add_constant(df_1[l[1]])
model = sm.OLS(df_1[l[0]], x).fit()
result = model.rsquared
allResults.append(result)
print (allResults)
Captura de pantalla 3:

Y esto es bastante impresionante, pero terriblemente ineficiente para listas más largas de variables.
Mi intento de combinaciones de listas:
Siguiendo las sugerencias deCómo generar todas las permutaciones de una lista en Python yConvierta una lista de tuplas en una lista de listas Puedo configurar una combinación de TODAS las variables como esta:
Fragmento de código 4:
allTuples = list(itertools.permutations(listVars))
allCombos = [list(elem) for elem in allTuples]
Captura de pantalla 4:
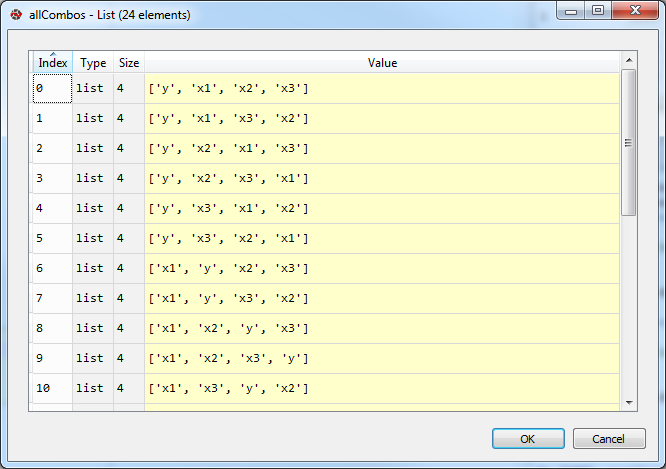
Y eso es muy divertido, pero no me da el enfoque gradual que busco. De todos modos, espero que algunos de ustedes encuentren esto interesante.
Gracias por cualquier sugerencia!