Keras usando el backend de Tensorflow: enmascaramiento en la función de pérdida
Estoy tratando de implementar una tarea secuencia a secuencia usando LSTM de Keras con el backend Tensorflow. Las entradas son oraciones en inglés con longitudes variables. Para construir un conjunto de datos con forma bidimensional [número_batch, max_sentence_length], agrego EOF al final de la línea y rellena cada oración con suficientes marcadores de posición, p. "#". Y luego, cada carácter en la oración se transforma en un vector caliente, ahora el conjunto de datos tiene forma tridimensional [número_batch, max_sentence_length, character_number]. Después de las capas del codificador y decodificador LSTM, se calcula la entropía cruzada softmax entre la salida y el objetivo.
Para eliminar el efecto de relleno en el entrenamiento del modelo, se podría usar el enmascaramiento en la función de entrada y pérdida. La entrada de máscara en Keras se puede hacer usando "layers.core.Masking". En Tensorflow, el enmascaramiento de la función de pérdida se puede hacer de la siguiente manera:función de pérdida enmascarada personalizada en Tensorflow
Sin embargo, no encuentro una manera de realizarlo en Keras, ya que una función de pérdida definida en Keras solo acepta los parámetros y_true y y_pred. Entonces, ¿cómo ingresar longitudes_secuencia verdaderas para la función de pérdida y la máscara?
Además, encuentro una función "_weighted_masked_objective (fn)" en \ keras \ engine \ training.py. Su definición es "Agrega soporte para enmascarar y ponderar muestras a una función objetivo". Pero parece que la función solo puede aceptar fn (y_true, y_pred). ¿Hay alguna manera de usar esta función para resolver mi problema?
Para ser específico, modifico el ejemplo de Yu-Yang.
from keras.models import Model
from keras.layers import Input, Masking, LSTM, Dense, RepeatVector, TimeDistributed, Activation
import numpy as np
from numpy.random import seed as random_seed
random_seed(123)
max_sentence_length = 5
character_number = 3 # valid character 'a, b' and placeholder '#'
input_tensor = Input(shape=(max_sentence_length, character_number))
masked_input = Masking(mask_value=0)(input_tensor)
encoder_output = LSTM(10, return_sequences=False)(masked_input)
repeat_output = RepeatVector(max_sentence_length)(encoder_output)
decoder_output = LSTM(10, return_sequences=True)(repeat_output)
output = Dense(3, activation='softmax')(decoder_output)
model = Model(input_tensor, output)
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.summary()
X = np.array([[[0, 0, 0], [0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 1, 0]],
[[0, 0, 0], [0, 1, 0], [1, 0, 0], [0, 1, 0], [0, 1, 0]]])
y_true = np.array([[[0, 0, 1], [0, 0, 1], [1, 0, 0], [0, 1, 0], [0, 1, 0]], # the batch is ['##abb','#babb'], padding '#'
[[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 0], [0, 1, 0]]])
y_pred = model.predict(X)
print('y_pred:', y_pred)
print('y_true:', y_true)
print('model.evaluate:', model.evaluate(X, y_true))
# See if the loss computed by model.evaluate() is equal to the masked loss
import tensorflow as tf
logits=tf.constant(y_pred, dtype=tf.float32)
target=tf.constant(y_true, dtype=tf.float32)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(target * tf.log(logits),axis=2))
losses = -tf.reduce_sum(target * tf.log(logits),axis=2)
sequence_lengths=tf.constant([3,4])
mask = tf.reverse(tf.sequence_mask(sequence_lengths,maxlen=max_sentence_length),[0,1])
losses = tf.boolean_mask(losses, mask)
masked_loss = tf.reduce_mean(losses)
with tf.Session() as sess:
c_e = sess.run(cross_entropy)
m_c_e=sess.run(masked_loss)
print("tf unmasked_loss:", c_e)
print("tf masked_loss:", m_c_e)
La salida en Keras y Tensorflow se compara de la siguiente manera:
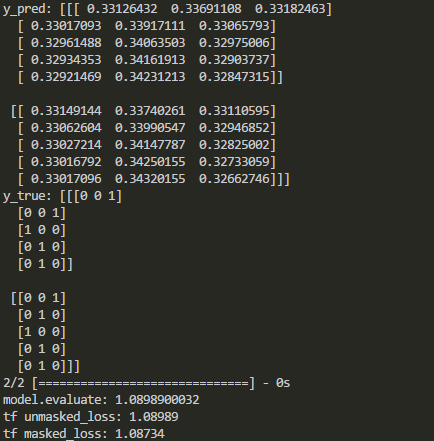
{kind=link}
Como se muestra arriba, el enmascaramiento se desactiva después de algunos tipos de capas. Entonces, ¿cómo enmascarar la función de pérdida en keras cuando se agregan esas capas?