(см. мое последнее редактирование), и общая картина остается прежней, хотя прогнозы выглядят немного иначе.
я есть набор данных временных рядов, и я пытаюсь обучить сеть так, чтобы онаoverfits (очевидно, это только первый шаг, я буду бороться с переоснащением).
Сеть имеет два уровня: LSTM (32 нейрона) и Dense (1 нейрон, без активации).
Тренинг / модель имеет следующие параметры:epochs: 20, steps_per_epoch: 100, loss: "mse", optimizer: "rmsprop".
TimeseriesGenerator производит входные серии с:length: 1, sampling_rate: 1, batch_size: 1.
Я ожидал бы, что сеть просто запомнит такой маленький набор данных (я пробовал даже гораздо более сложную сеть безрезультатно), и потери на обучающем наборе данных были бы почти нулевыми. Это не так, и когда я представляю результаты натренировка установить так:
y_pred = model.predict_generator(gen)
plot_points = 40
epochs = range(1, plot_points + 1)
pred_points = numpy.resize(y_pred[:plot_points], (plot_points,))
target_points = gen.targets[:plot_points]
plt.plot(epochs, pred_points, 'b', label='Predictions')
plt.plot(epochs, target_points, 'r', label='Targets')
plt.legend()
plt.show()
Я получил:
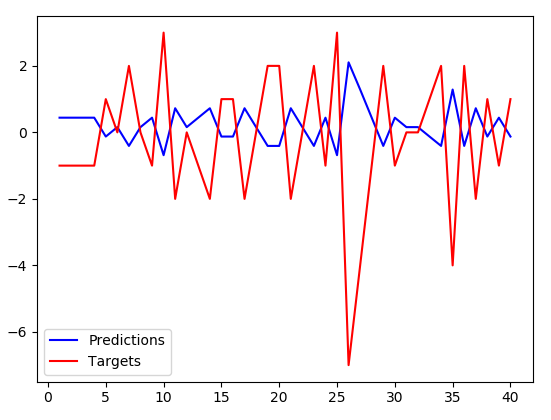
Прогнозы имеют несколько меньшую амплитуду, ноточно обратный к целям. Btw. это не запоминается, они инвертируются даже для тестового набора данных, который алгоритм не обучил вообще. Похоже, что вместо запоминания набора данных моя сеть только что научилась отрицать входное значение и немного уменьшать его.Есть идеи, почему это происходит? Не похоже, что решение, к которому оптимизатор должен был сойтись (потери довольно большие).
РЕДАКТИРОВАТЬ (некоторые соответствующие части моего кода):
train_gen = keras.preprocessing.sequence.TimeseriesGenerator(
x,
y,
length=1,
sampling_rate=1,
batch_size=1,
shuffle=False
)
model = Sequential()
model.add(LSTM(32, input_shape=(1, 1), return_sequences=False))
model.add(Dense(1, input_shape=(1, 1)))
model.compile(
loss="mse",
optimizer="rmsprop",
metrics=[keras.metrics.mean_squared_error]
)
history = model.fit_generator(
train_gen,
epochs=20,
steps_per_epoch=100
)
РЕДАКТИРОВАТЬ (другой, случайно сгенерированный набор данных):

Мне пришлось увеличить количество нейронов LSTM до 256, с предыдущей настройкой (32 нейрона) синяя линия была почти плоской. Тем не менее, с увеличением возникает та же картина -обратные предсказания с несколько меньшей амплитудой.
РЕДАКТИРОВАТЬ (цели смещены на +1):

Смещение целей на единицу по сравнению с предсказаниями не дает намного лучшего соответствия. Обратите внимание на выделенные части, где график не просто чередуется, он более заметен.
РЕДАКТИРОВАТЬ (увеличена длина до 2 ...TimeseriesGenerator(length=2, ...)):

С участиемlength=2 предсказания перестают так близко отслеживать цели, но общая картина инверсии остается неизменной.