Я надеюсь, у меня есть лучший рабочий пример, чтобы показать пункты выше. Я добавлю этот ответ в качестве заполнителя и вернусь и добавлю больше материала, если у меня будет шанс.
аюсь создать глубокий CNN, который может классифицировать каждый отдельный пиксель в изображении. Я копирую архитектуру из изображения ниже, взятого изэто бумага. В статье упоминается, что деконволюции используются так, что возможен любой размер ввода. Это можно увидеть на изображении ниже.
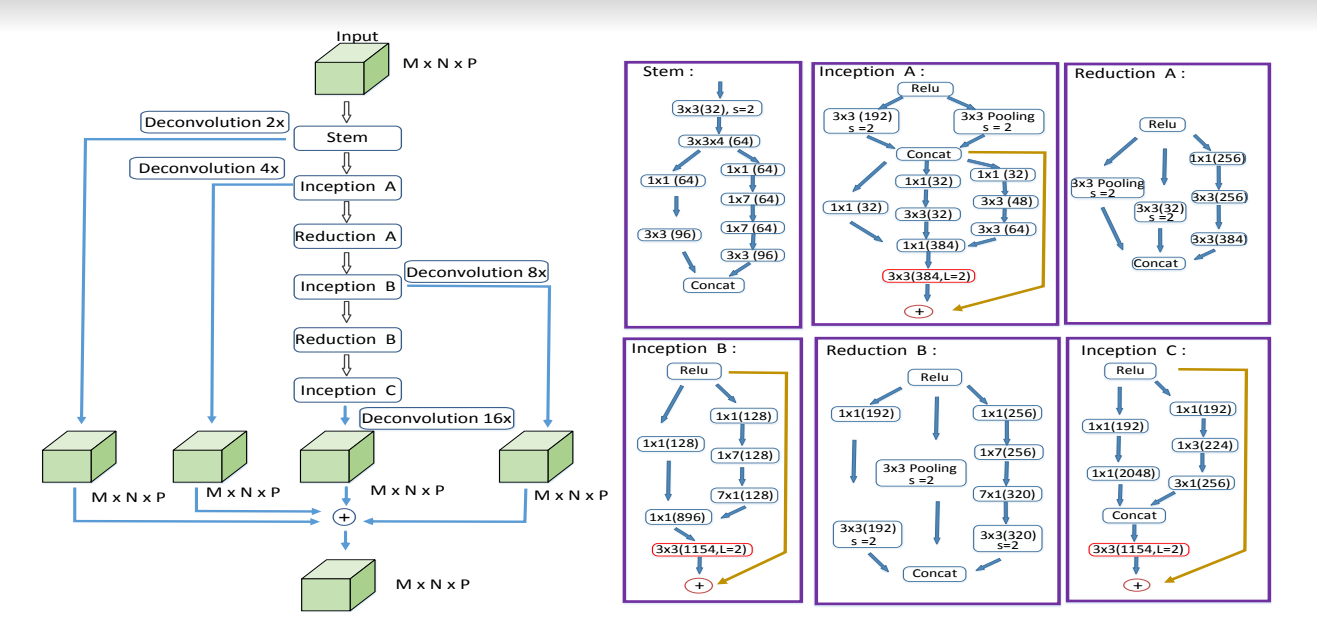
В настоящее время я жестко запрограммировал свою модель для приема изображений размером 32x32x7, но я хотел бы принять любой размер ввода.Какие изменения мне нужно было бы внести в мой код, чтобы принимать ввод переменного размера?
x = tf.placeholder(tf.float32, shape=[None, 32*32*7])
y_ = tf.placeholder(tf.float32, shape=[None, 32*32*7, 3])
...
DeConnv1 = tf.nn.conv3d_transpose(layer1, filter = w, output_shape = [1,32,32,7,1], strides = [1,2,2,2,1], padding = 'SAME')
...
final = tf.reshape(final, [1, 32*32*7])
W_final = weight_variable([32*32*7,32*32*7,3])
b_final = bias_variable([32*32*7,3])
final_conv = tf.tensordot(final, W_final, axes=[[1], [1]]) + b_final