Diferença de desempenho: std :: acumulate vs std :: inner_product vs Loop
Hoje, quero compartilhar algo que me surpreendeu ao tentar implementar esta operação simples:

Encontrei maneiras diferentes de executar a mesma operação:
Usando ostd::inner_product.Implementando um predicado e usando ostd::accumulate função.Usando um loop no estilo C.Eu queria realizar um benchmark usando o Quick Bench e ativando todas as otimizações.
Antes de tudo, comparei as duas alternativas C ++ com valores flutuantes. Este é o código usado usandostd::accumulate:
const auto predicate = [](const double previous, const double current) {
return previous + current * current;
};
const auto result = std::accumulate(input.cbegin(), input.cend(), 0, predicate);
Versus esse código usando ostd::inner_product funcionalidade:
const auto result = std::inner_product(input.cbegin(), input.cend(), input.cbegin(), 1);
Depois de executar o benchmark com toda a otimização ativada, obtive este resultado:
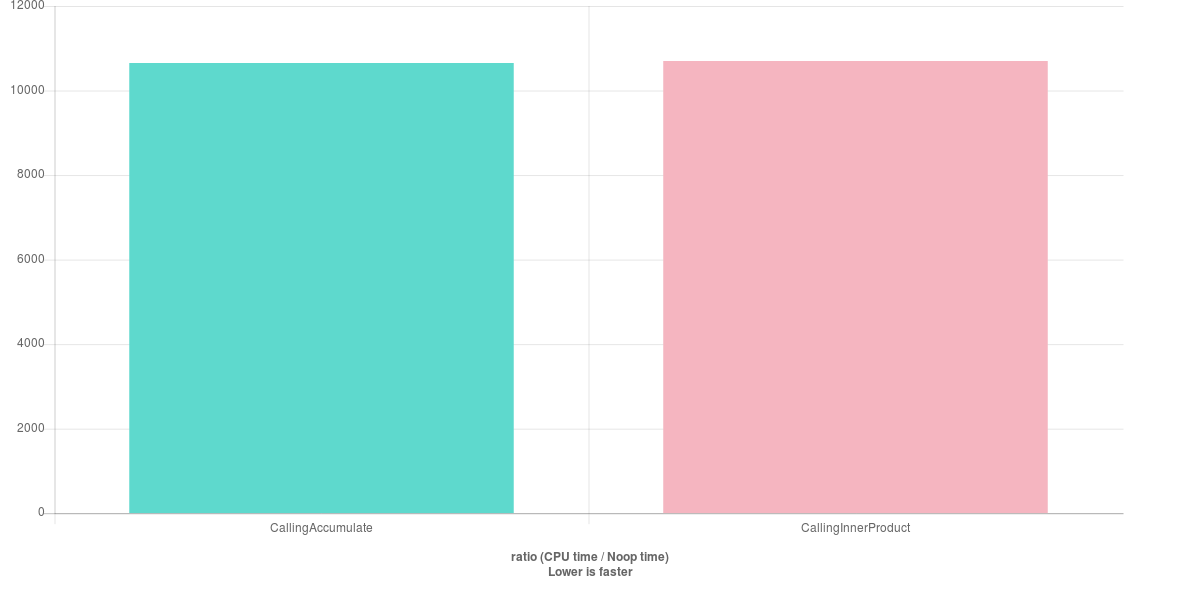
Ambos os algoritmos parecem atingir o mesmo desempenho. Eu queria ir mais longe e tentar a implementação C:
double result = 0;
for (auto i = 0; i < input.size(); ++i) {
result += input[i] * input[i];
}
E surpreendentemente, descobri:
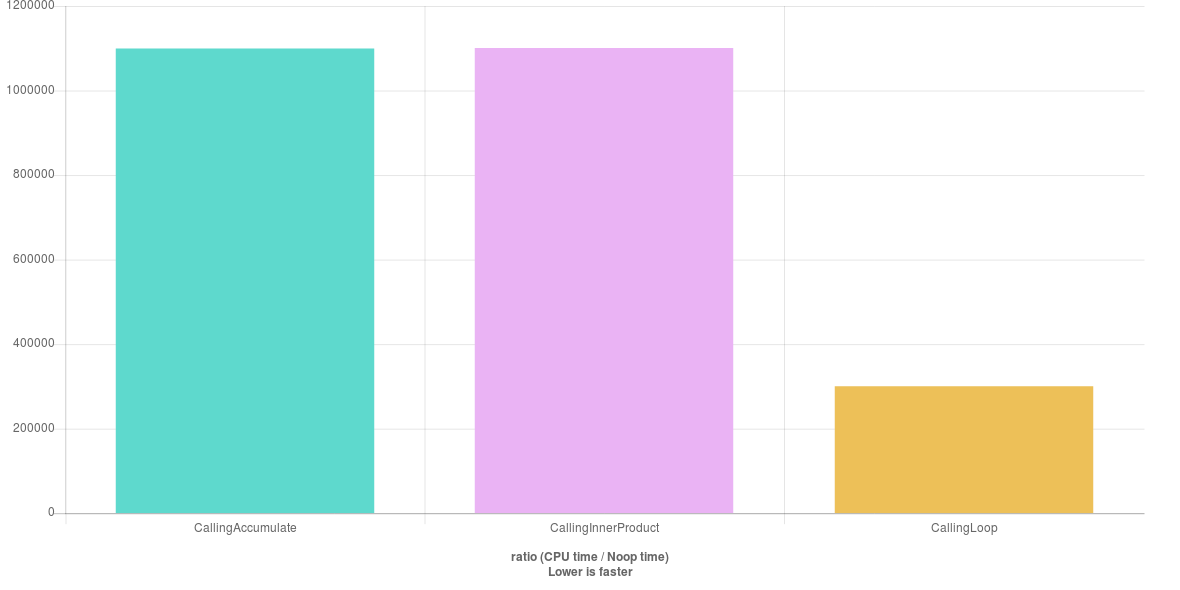
Eu não estava esperando esse resultado. Eu tinha certeza de que havia algo errado, então verifiquei a implementação do GCC:
template<typename _InputIterator1, typename _InputIterator2, typename _Tp>
inline _Tp
inner_product(_InputIterator1 __first1, _InputIterator1 __last1,
_InputIterator2 __first2, _Tp __init)
{
// concept requirements
__glibcxx_function_requires(_InputIteratorConcept<_InputIterator1>)
__glibcxx_function_requires(_InputIteratorConcept<_InputIterator2>)
__glibcxx_requires_valid_range(__first1, __last1);
for (; __first1 != __last1; ++__first1, (void)++__first2)
__init = __init + (*__first1 * *__first2);
return __init;
}
Eu descobri que estava fazendo o mesmo que a implementação em C. Depois de revisar a implementação, descobri algo estranho (ou pelo menos não esperava ter esse impacto significativo): em todas as acumulações internas, ele fazia uma conversão do iterador value_type para o tipo do valor inicial.
No meu caso, eu estava inicializando os valores iniciais para 0 ou 1, os valores foram considerados inteiros e em cada acumulação, o compilador estava fazendo o casting. Nos diferentes casos de teste, minha matriz de entrada armazena pontos flutuantes truncados, para que o resultado não seja alterado.
Após atualizar o valor inicial para um tipo duplo:
const auto result = std::accumulate(input.cbegin(), input.cend(), 0.0, predicate);
E:
const auto result = std::inner_product(input.cbegin(), input.cend(), input.cbegin(), 0.0);
Eu obtive o resultado esperado:
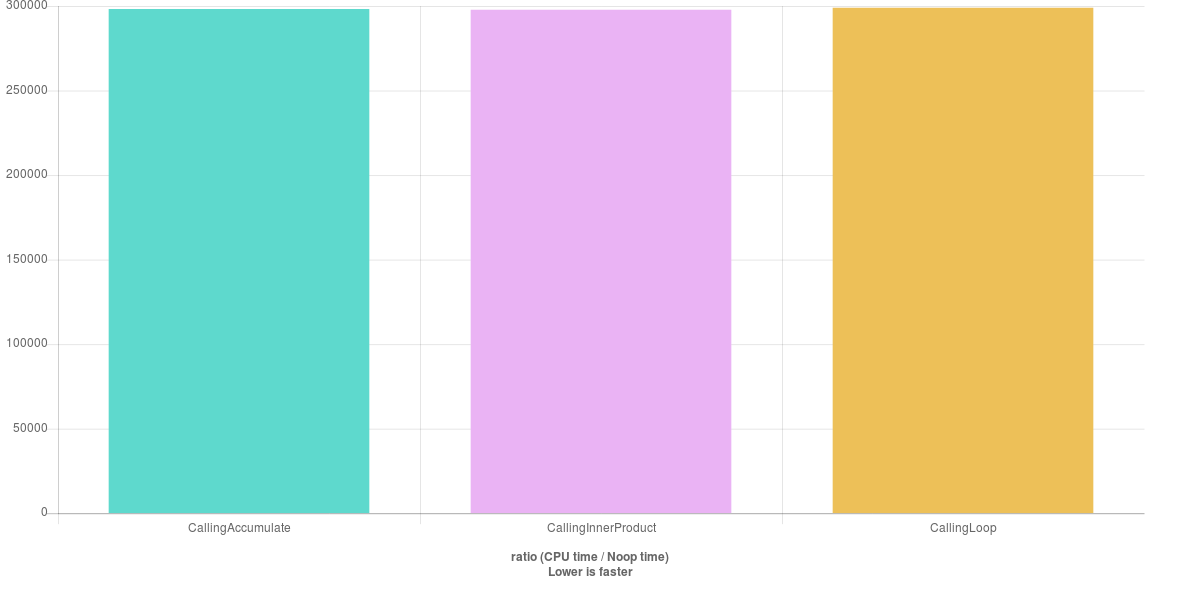
Agora, entendo que deixar o valor inicial como um tipo independente do tipo subjacente do iterador pode tornar a função mais flexível e permitir fazer mais coisas. Mas,
Se estou acumulando elementos de uma matriz, espero obter o mesmo tipo como resultado. O mesmo para o produto interno.
Deve ser o comportamento padrão?
Por que o padrão decidiu realizá-lo dessa maneira?