не реже (возможно, даже больше), чем когда они совпадают.
ня я хочу поделиться тем, что поражало меня, когда я пытался реализовать эту простую операцию:

Я нашел разные способы выполнить одну и ту же операцию:
Используяstd::inner_product.Реализация предиката и использованиеstd::accumulate функция.Использование цикла в стиле C.Я хотел выполнить некоторые тесты, используя Quick Bench и включив все оптимизации.
Прежде всего, я сравнил две альтернативы C ++ с плавающими значениями. Это код, используемый с помощьюstd::accumulate:
const auto predicate = [](const double previous, const double current) {
return previous + current * current;
};
const auto result = std::accumulate(input.cbegin(), input.cend(), 0, predicate);
По сравнению с этим кодом с помощьюstd::inner_product функциональность:
const auto result = std::inner_product(input.cbegin(), input.cend(), input.cbegin(), 1);
После запуска теста с включенной оптимизацией я получил такой результат:
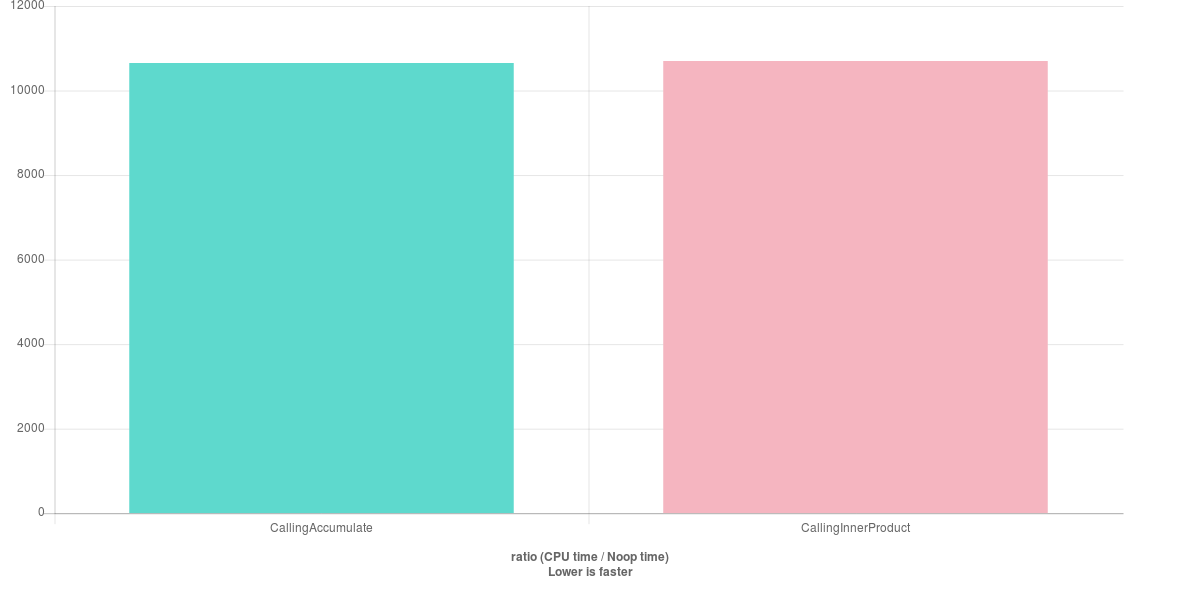
Оба алгоритма, кажется, достигают одинаковой производительности. Я хотел пойти дальше и попробовать реализацию C:
double result = 0;
for (auto i = 0; i < input.size(); ++i) {
result += input[i] * input[i];
}
И удивительно, я обнаружил:
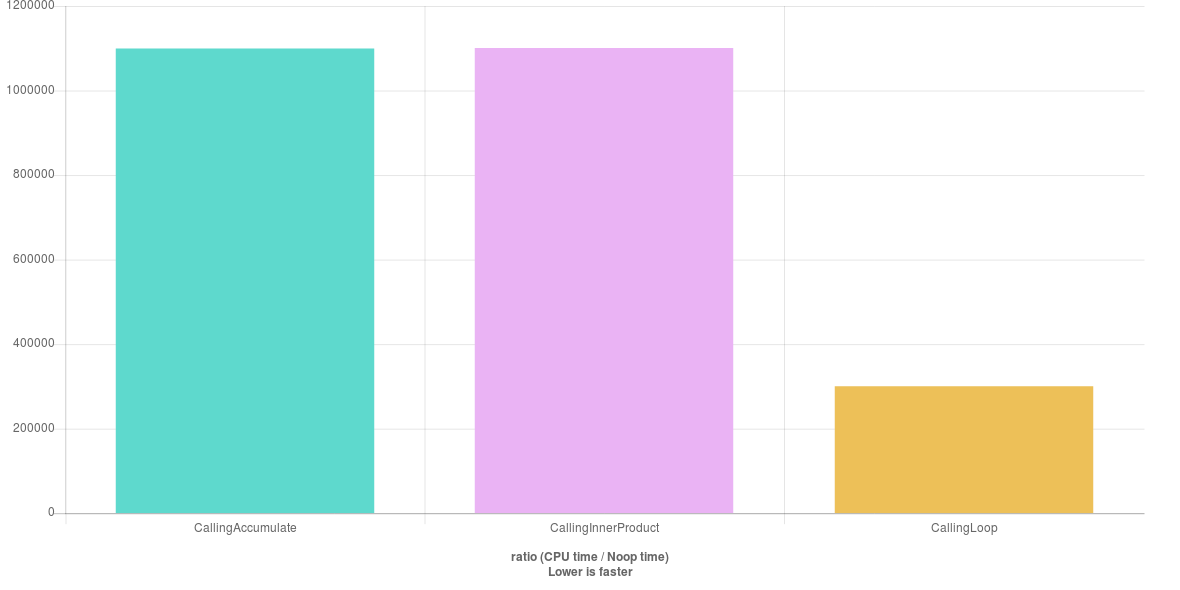
Я не ожидал этого результата. Я был уверен, что что-то не так, поэтому я проверил реализацию GCC:
template<typename _InputIterator1, typename _InputIterator2, typename _Tp>
inline _Tp
inner_product(_InputIterator1 __first1, _InputIterator1 __last1,
_InputIterator2 __first2, _Tp __init)
{
// concept requirements
__glibcxx_function_requires(_InputIteratorConcept<_InputIterator1>)
__glibcxx_function_requires(_InputIteratorConcept<_InputIterator2>)
__glibcxx_requires_valid_range(__first1, __last1);
for (; __first1 != __last1; ++__first1, (void)++__first2)
__init = __init + (*__first1 * *__first2);
return __init;
}
Я обнаружил, что он делает то же самое, что и реализация C. Изучив реализацию, я обнаружил нечто странное (или, по крайней мере, я не ожидал, что это окажет такое значительное влияние): во всех внутренних накоплениях он выполнял приведение типа итератора value_type к типу начального значения.
В моем случае я инициализировал начальные значения 0 или 1, значения считались целыми числами, и в каждом накоплении компилятор выполнял приведение. В разных тестовых примерах мой входной массив хранит усеченные плавающие точки, поэтому результат не изменился.
После обновления начального значения до двойного типа:
const auto result = std::accumulate(input.cbegin(), input.cend(), 0.0, predicate);
А также:
const auto result = std::inner_product(input.cbegin(), input.cend(), input.cbegin(), 0.0);
Я получил ожидаемый результат:
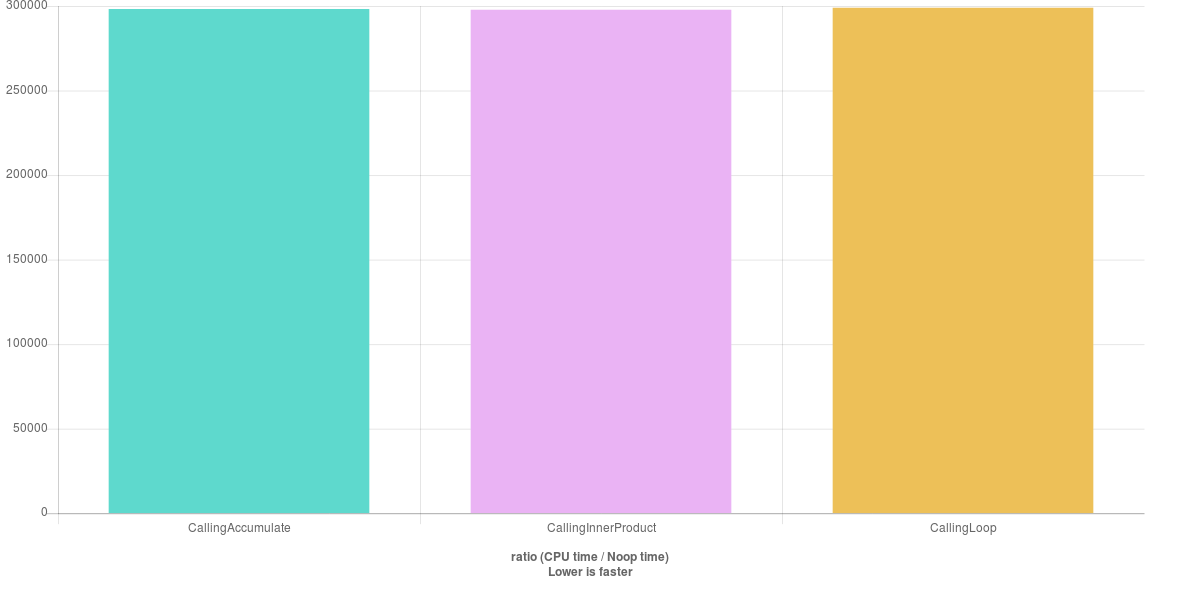
Теперь я понимаю, что оставление начального значения независимым типом от базового типа итератора может сделать функцию более гибкой и позволить делать больше вещей. Но,
Если я накапливаю элементы массива, я ожидаю получить тот же тип в результате. То же самое для внутреннего продукта.
Должно ли это быть поведение по умолчанию?
Почему стандарт решил выполнить это таким образом?