Como as tarefas são distribuídas dentro de um cluster Spark?
Então, eu tenho uma entrada que consiste em um conjunto de dados e vários algoritmos ML (com ajuste de parâmetros) usando o scikit-learn. Eu tentei algumas tentativas de como executar isso da maneira mais eficiente possível, mas neste momento ainda não tenho a infraestrutura adequada para avaliar meus resultados. No entanto, não tenho conhecimento de fundo nesta área e preciso de ajuda para esclarecer as coisas.
Basicamente, quero saber como as tarefas são distribuídas de forma a explorar o máximo possível todos os recursos disponíveis e o que é realmente feito implicitamente (por exemplo, pelo Spark) e o que não é.
Este é o meu cenário:
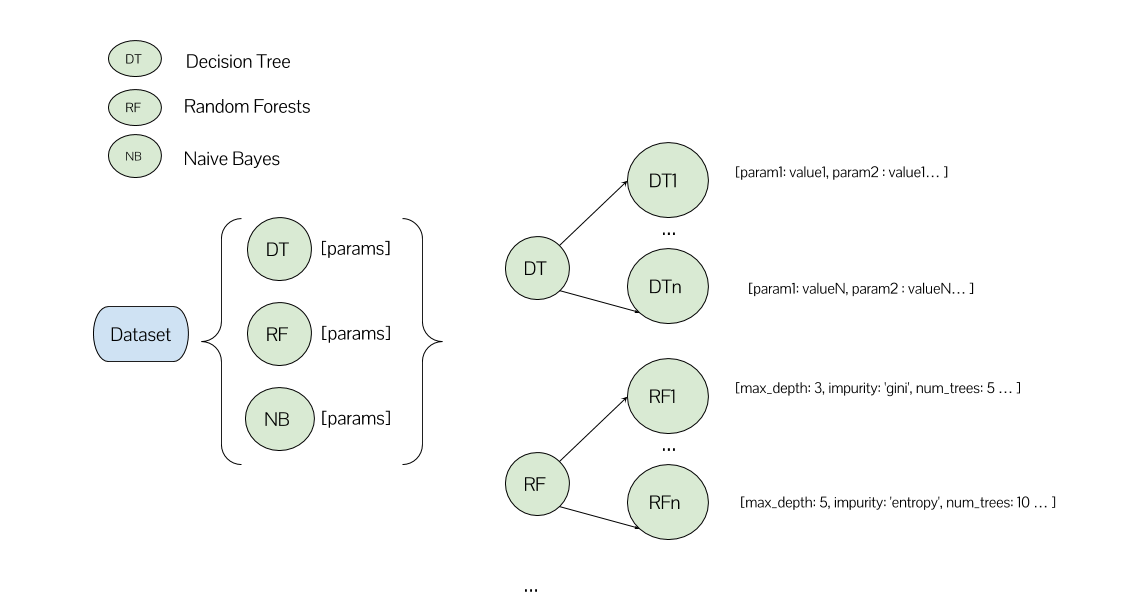
Preciso treinar muitos modelos diferentes de Árvore de Decisão (tantos quanto a combinação de todos os parâmetros possíveis), muitos modelos diferentes de Floresta Aleatória e assim por diante ...
Em uma das minhas abordagens, tenho uma lista e cada um de seus elementos corresponde a um algoritmo de ML e sua lista de parâmetros.
spark.parallelize(algorithms).map(lambda algorihtm: run_experiment(dataframe, algorithm))
Nesta funçãorun_experiment Eu crio umGridSearchCV para o algoritmo ML correspondente com sua grade de parâmetros. Eu também definon_jobs=-1 para (tentar) alcançar o paralelismo máximo.
Nesse contexto, no meu cluster Spark com alguns nós, faz sentido que a execução se pareça com isso?
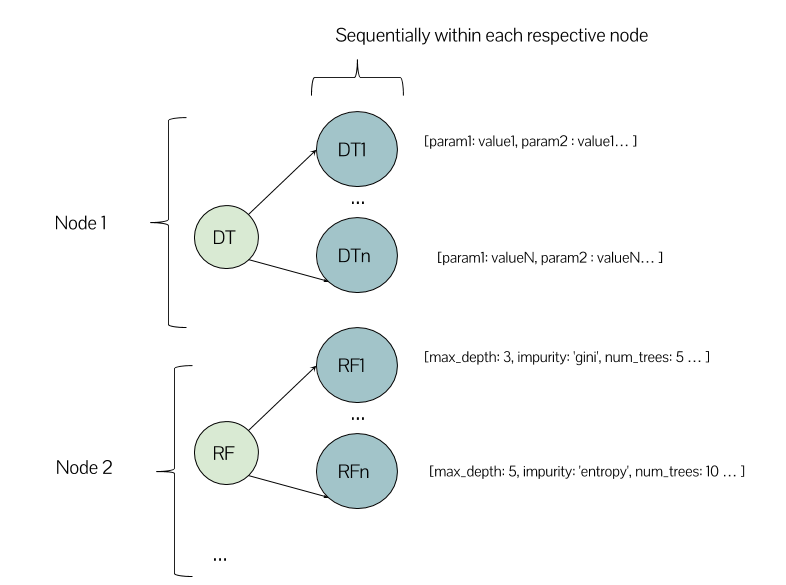
Ou pode haver um modelo de Árvore de Decisão e também um modelo de Floresta Aleatória em execução no mesmo nó? Esta é a minha primeira experiência usando um ambiente de cluster, por isso estou um pouco confuso sobre como esperar que as coisas funcionem.
Por outro lado, o que muda exatamente em termos de execução, se em vez da primeira abordagem comparallelizeEu uso umfor loop para iterar sequencialmente na minha lista de algoritmos e criar oGridSearchCV usando databricksspark-sklearn integração entre Spark e scikit-learn? A maneira como é ilustrado na documentação parece algo como isto:

Finalmente, com relação a essa segunda abordagem, usando os mesmos algoritmos de ML, mas com o Spark MLlib em vez do scikit-learn, toda a paralelização / distribuição seria resolvida?
Desculpe se a maior parte disso é um pouco ingênua, mas eu realmente aprecio quaisquer respostas ou idéias sobre isso. Eu queria entender o básico antes de testar no cluster e brincar com os parâmetros de agendamento de tarefas.
Não tenho certeza se esta pergunta é mais adequada aqui ou no CS stackexchange.