¿Cómo se distribuyen las tareas dentro de un clúster de Spark?
Entonces tengo una entrada que consiste en un conjunto de datos y varios algoritmos de ML (con ajuste de parámetros) usando scikit-learn. He intentado bastantes intentos sobre cómo ejecutar esto de la manera más eficiente posible, pero en este momento todavía no tengo la infraestructura adecuada para evaluar mis resultados. Sin embargo, me falta algo de experiencia en esta área y necesito ayuda para aclarar las cosas.
Básicamente, quiero saber cómo se distribuyen las tareas de una manera que aproveche al máximo todos los recursos disponibles, y qué se hace implícitamente (por ejemplo, Spark) y qué no.
Este es mi escenario:
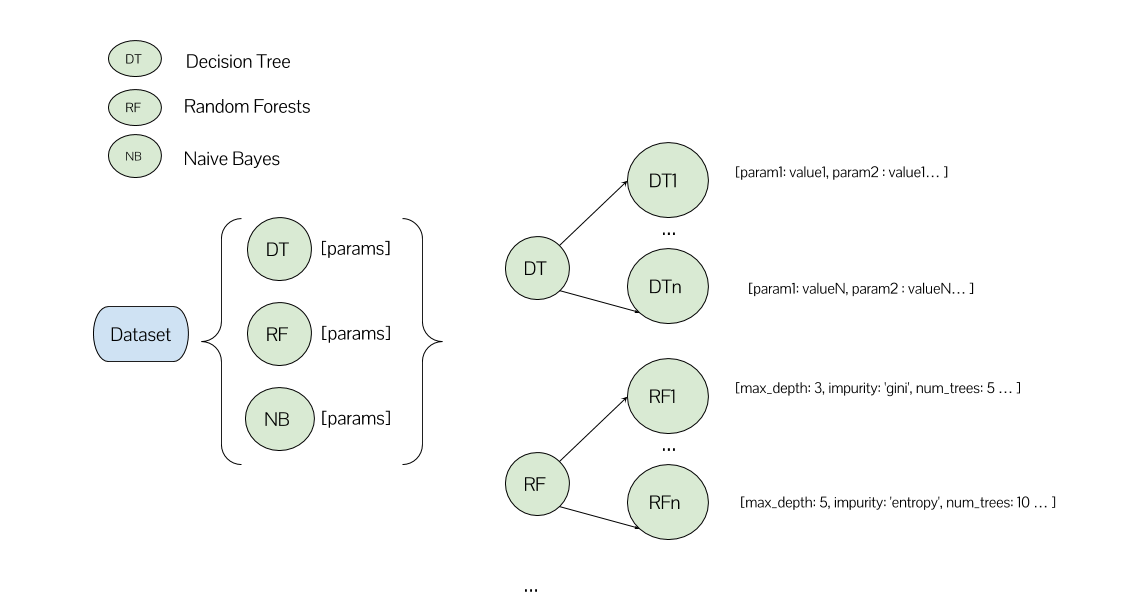
Necesito entrenar muchos modelos diferentes de Árbol de decisión (tantos como la combinación de todos los parámetros posibles), muchos modelos diferentes de Bosque aleatorio, etc.
En uno de mis enfoques, tengo una lista y cada uno de sus elementos corresponde a un algoritmo ML y su lista de parámetros.
spark.parallelize(algorithms).map(lambda algorihtm: run_experiment(dataframe, algorithm))
En esta funciónrun_experiment Creo unGridSearchCV para el algoritmo ML correspondiente con su cuadrícula de parámetros. Yo también pusen_jobs=-1 para (intentar) lograr el máximo paralelismo.
En este contexto, en mi clúster Spark con algunos nodos, ¿tiene sentido que la ejecución se parezca a esto?
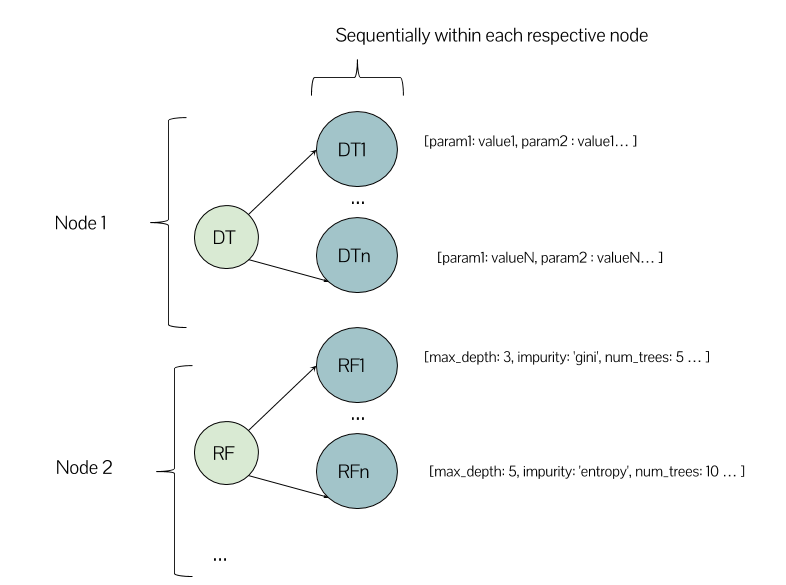
¿O puede haber un modelo de árbol de decisión y también un modelo de bosque aleatorio ejecutándose en el mismo nodo? Esta es mi primera experiencia usando un entorno de clúster, así que estoy un poco confundido sobre cómo esperar que las cosas funcionen.
Por otro lado, qué cambia exactamente en términos de ejecución, si en lugar del primer enfoque conparallelize, Uso unfor bucle para iterar secuencialmente a través de mi lista de algoritmos y crear elGridSearchCV usando databrickschispa-sklearn integración entre Spark y scikit-learn? La forma en que se ilustra en la documentación parece algo así:

Finalmente, con respecto a este segundo enfoque, usando los mismos algoritmos de ML pero en lugar de Spark MLlib en lugar de scikit-learn, ¿se resolvería toda la paralelización / distribución?
Lo siento si la mayoría de esto es un poco ingenuo, pero realmente agradezco cualquier respuesta o idea sobre esto. Quería comprender los conceptos básicos antes de probar realmente en el clúster y jugar con los parámetros de programación de tareas.
No estoy seguro de si esta pregunta es más adecuada aquí o en CS stackexchange.