Escalonamento e ajuste a uma distribuição log-normal usando um eixo logarítmico em python
Eu tenho um conjunto distribuído de log-normal de amostras. Eu posso visualizar as amostras usando um histrograma com eixo x linear ou logarítmico. Posso fazer um ajuste no histograma para obter o PDF e depois escalá-lo para o histrograma no gráfico com o eixo x linear. Veja tambémesta pergunta postada anteriormente.
No entanto, não consigo plotar corretamente o PDF na plotagem com o eixo x logarítmico.
Infelizmente, não é apenas um problema com o dimensionamento da área do PDF para o histograma, mas o PDF também é deslocado para a esquerda, como você pode ver na plotagem a seguir.
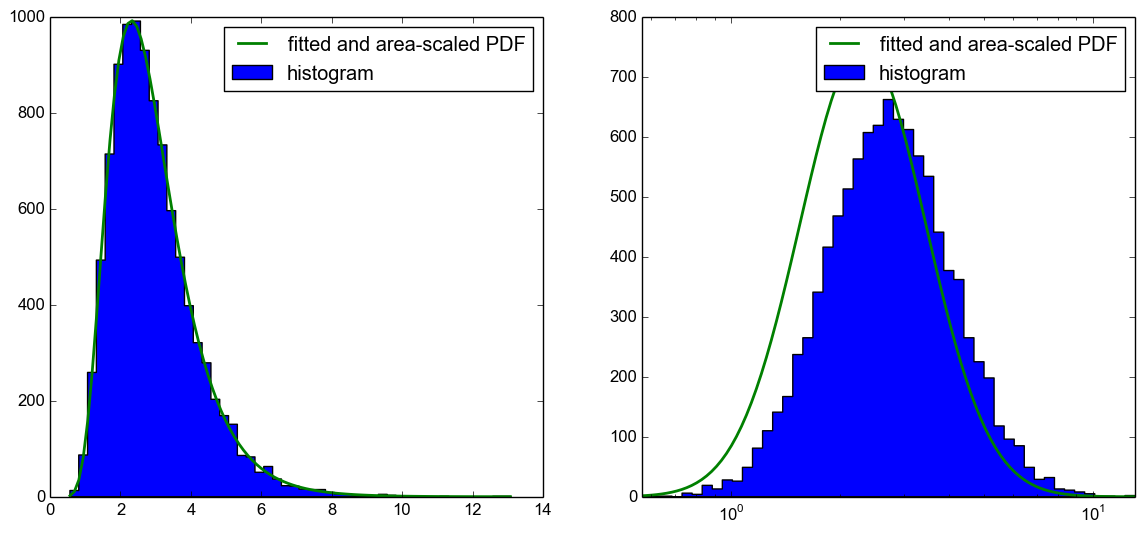
Minha pergunta agora é: o que estou fazendo de errado aqui? Usando o CDF para plotar o histograma esperado,como sugerido nesta resposta, trabalho. Gostaria apenas de saber o que estou fazendo de errado neste código, pois, no meu entendimento, ele também deve funcionar.
Este é o código python (desculpe-me por ser um pouco longo, mas eu queria postar uma "versão autônoma completa"):
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats
# generate log-normal distributed set of samples
np.random.seed(42)
samples = np.random.lognormal( mean=1, sigma=.4, size=10000 )
# make a fit to the samples
shape, loc, scale = scipy.stats.lognorm.fit( samples, floc=0 )
x_fit = np.linspace( samples.min(), samples.max(), 100 )
samples_fit = scipy.stats.lognorm.pdf( x_fit, shape, loc=loc, scale=scale )
# plot a histrogram with linear x-axis
plt.subplot( 1, 2, 1 )
N_bins = 50
counts, bin_edges, ignored = plt.hist( samples, N_bins, histtype='stepfilled', label='histogram' )
# calculate area of histogram (area under PDF should be 1)
area_hist = .0
for ii in range( counts.size):
area_hist += (bin_edges[ii+1]-bin_edges[ii]) * counts[ii]
# oplot fit into histogram
plt.plot( x_fit, samples_fit*area_hist, label='fitted and area-scaled PDF', linewidth=2)
plt.legend()
# make a histrogram with a log10 x-axis
plt.subplot( 1, 2, 2 )
# equally sized bins (in log10-scale)
bins_log10 = np.logspace( np.log10( samples.min() ), np.log10( samples.max() ), N_bins )
counts, bin_edges, ignored = plt.hist( samples, bins_log10, histtype='stepfilled', label='histogram' )
# calculate area of histogram
area_hist_log = .0
for ii in range( counts.size):
area_hist_log += (bin_edges[ii+1]-bin_edges[ii]) * counts[ii]
# get pdf-values for log10 - spaced intervals
x_fit_log = np.logspace( np.log10( samples.min()), np.log10( samples.max()), 100 )
samples_fit_log = scipy.stats.lognorm.pdf( x_fit_log, shape, loc=loc, scale=scale )
# oplot fit into histogram
plt.plot( x_fit_log, samples_fit_log*area_hist_log, label='fitted and area-scaled PDF', linewidth=2 )
plt.xscale( 'log' )
plt.xlim( bin_edges.min(), bin_edges.max() )
plt.legend()
plt.show()
Atualização 1:
Esqueci de mencionar as versões que estou usando:
python 2.7.6
numpy 1.8.2
matplotlib 1.3.1
scipy 0.13.3
Atualização 2:
Conforme apontado por @Christoph e @zaxliu (graças a ambos), o problema está na escala do PDF. Funciona quando estou usando as mesmas caixas do histograma, como na solução do @ zaxliu, mas ainda tenho alguns problemas ao usar uma resolução mais alta para o PDF (como no meu exemplo acima). Isto é mostrado na figura a seguir:
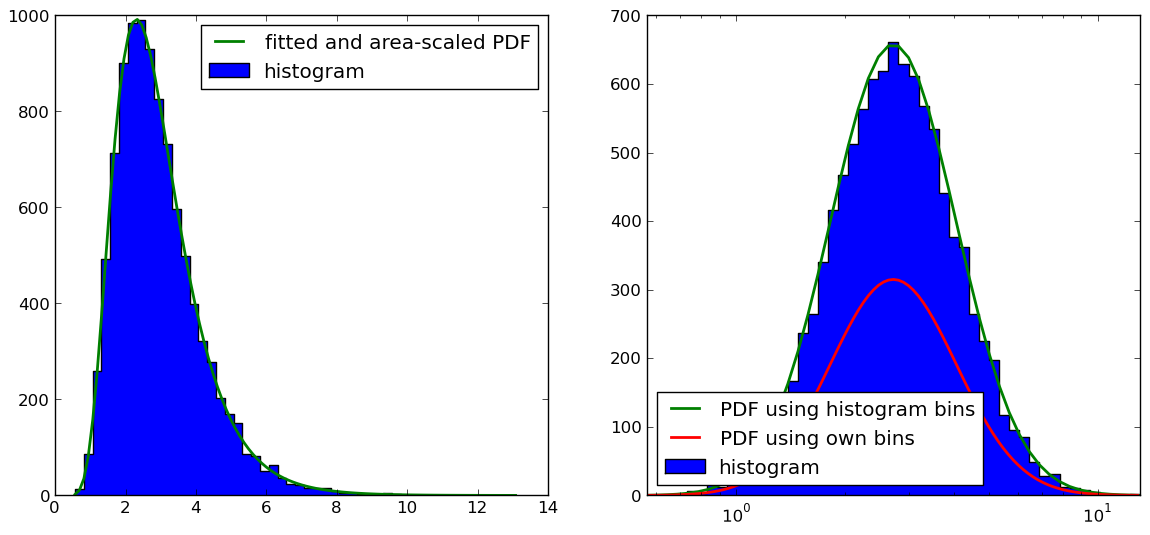
O código para a figura no lado direito é (deixei de fora o material de importação e geração de amostra de dados, que você pode encontrar no exemplo acima):
# equally sized bins in log10-scale
bins_log10 = np.logspace( np.log10( samples.min() ), np.log10( samples.max() ), N_bins )
counts, bin_edges, ignored = plt.hist( samples, bins_log10, histtype='stepfilled', label='histogram' )
# calculate length of each bin (required for scaling PDF to histogram)
bins_log_len = np.zeros( bins_log10.size )
for ii in range( counts.size):
bins_log_len[ii] = bin_edges[ii+1]-bin_edges[ii]
# get pdf-values for same intervals as histogram
samples_fit_log = scipy.stats.lognorm.pdf( bins_log10, shape, loc=loc, scale=scale )
# oplot fitted and scaled PDF into histogram
plt.plot( bins_log10, np.multiply(samples_fit_log,bins_log_len)*sum(counts), label='PDF using histogram bins', linewidth=2 )
# make another pdf with a finer resolution
x_fit_log = np.logspace( np.log10( samples.min()), np.log10( samples.max()), 100 )
samples_fit_log = scipy.stats.lognorm.pdf( x_fit_log, shape, loc=loc, scale=scale )
# calculate length of each bin (required for scaling PDF to histogram)
# in addition, estimate middle point for more accuracy (should in principle also be done for the other PDF)
bins_log_len = np.diff( x_fit_log )
samples_log_center = np.zeros( x_fit_log.size-1 )
for ii in range( x_fit_log.size-1 ):
samples_log_center[ii] = .5*(samples_fit_log[ii] + samples_fit_log[ii+1] )
# scale PDF to histogram
# NOTE: THIS IS NOT WORKING PROPERLY (SEE FIGURE)
pdf_scaled2hist = np.multiply(samples_log_center,bins_log_len)*sum(counts)
# oplot fit into histogram
plt.plot( .5*(x_fit_log[:-1]+x_fit_log[1:]), pdf_scaled2hist, label='PDF using own bins', linewidth=2 )
plt.xscale( 'log' )
plt.xlim( bin_edges.min(), bin_edges.max() )
plt.legend(loc=3)