Calcular eficientemente la distancia ponderada en MATLAB
Varios publicaciones existe sobre el cálculo eficiente de distancias por pares en MATLAB. Estas publicaciones tienden a preocuparse por calcular rápidamente la distancia euclidiana entre un gran número de puntos.
Necesito crear una función que calcule rápidamente las diferencias por pares entre números más pequeños de puntos (típicamente menos de 1000 pares). Dentro del gran esquema del programa que estoy escribiendo, esta función se ejecutará miles de veces, por lo que incluso las pequeñas ganancias en eficiencia son importantes. La función debe ser flexible de dos maneras:
En cualquier llamada, la métrica de distancia puede ser euclidiana O bloque de ciudad.Las dimensiones de los datos están ponderadas.Por lo que puedo decir, no se ha publicado ninguna solución a este problema en particular. La caja de herramientas de estadísticas ofrecepdist ypdist2, que aceptan muchas funciones de distancia diferentes, pero no ponderación. He visto extensiones de estas funciones que permiten la ponderación, pero estas extensiones no permiten a los usuarios seleccionar diferentes funciones de distancia.
Idealmente, me gustaría evitar el uso de funciones de la caja de herramientas de estadísticas (no estoy seguro de que el usuario de la función tenga acceso a esas cajas de herramientas).
He escrito dos funciones para realizar esta tarea. El primero usa llamadas difíciles para repmat y permute, y el segundo simplemente usa bucles for.
function [D] = pairdist1(A, B, wts, distancemetric)
% get some information about the data
numA = size(A,1);
numB = size(B,1);
if strcmp(distancemetric,'cityblock')
r=1;
elseif strcmp(distancemetric,'euclidean')
r=2;
else error('Function only accepts "cityblock" and "euclidean" distance')
end
% format weights for multiplication
wts = repmat(wts,[numA,1,numB]);
% get featural differences between A and B pairs
A = repmat(A,[1 1 numB]);
B = repmat(permute(B,[3,2,1]),[numA,1,1]);
differences = abs(A-B).^r;
% weigh difference values before combining them
differences = differences.*wts;
differences = differences.^(1/r);
% combine features to get distance
D = permute(sum(differences,2),[1,3,2]);
end
Y:
function [D] = pairdist2(A, B, wts, distancemetric)
% get some information about the data
numA = size(A,1);
numB = size(B,1);
if strcmp(distancemetric,'cityblock')
r=1;
elseif strcmp(distancemetric,'euclidean')
r=2;
else error('Function only accepts "cityblock" and "euclidean" distance')
end
% use for-loops to generate differences
D = zeros(numA,numB);
for i=1:numA
for j=1:numB
differences = abs(A(i,:) - B(j,:)).^(1/r);
differences = differences.*wts;
differences = differences.^(1/r);
D(i,j) = sum(differences,2);
end
end
end
Aquí están las pruebas de rendimiento:
A = rand(10,3);
B = rand(80,3);
wts = [0.1 0.5 0.4];
distancemetric = 'cityblock';
tic
D1 = pairdist1(A,B,wts,distancemetric);
toc
tic
D2 = pairdist2(A,B,wts,distancemetric);
toc
Elapsed time is 0.000238 seconds.
Elapsed time is 0.005350 seconds.
Está claro que la versión repmat-and-permute funciona mucho más rápido que la versión de doble for-loop, al menos para conjuntos de datos más pequeños. Pero también sé que las llamadas a repmat a menudo ralentizan las cosas, sin embargo. Así que me pregunto si alguien en la comunidad SO tiene algún consejo que ofrecer para mejorar la eficiencia de cualquiera de las funciones.
EDITAR@Luis Mendo ofreció una buena limpieza de la función repmat-and-permute usandobsxfun. Comparé su función con mi original en conjuntos de datos de diferentes tamaños:
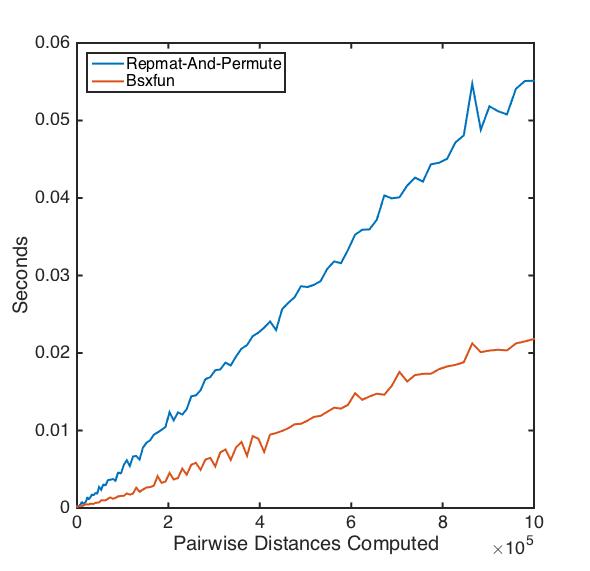
A medida que los datos se hacen más grandes, la versión bsxfun se convierte en el claro ganador.
EDITAR # 2He terminado de escribir la función y está disponible en github [enlazar] Terminé encontrando un método vectorizado bastante bueno para calcular la distancia euclidiana [enlazar], entonces uso ese método en el caso euclidiano, y tomé el de @ DivakarConsejo para la cuadra de la ciudad. Todavía no es tan rápido como pdist2, pero debe ser más rápido que cualquiera de los enfoques que expuse anteriormente en esta publicación, y acepta fácilmente las ponderaciones.