Cálculo eficiente da distância ponderada no MATLAB
De várias Postagens existir sobre o cálculo eficiente das distâncias aos pares no MATLAB. Esses postos tendem a se preocupar em calcular rapidamente a distância euclidiana entre um grande número de pontos.
Preciso criar uma função que calcule rapidamente as diferenças entre pares entre números menores de pontos (geralmente menores que 1000 pares). Dentro do esquema maior do programa que estou escrevendo, essa função será executada milhares de vezes, portanto, mesmo pequenos ganhos em eficiência são importantes. A função precisa ser flexível de duas maneiras:
Em qualquer chamada, a métrica da distância pode ser euclidiana OU bloco da cidade.As dimensões dos dados são ponderadas.Tanto quanto eu posso dizer, nenhuma solução para este problema específico foi publicada. A caixa de ferramentas estatísticas oferecepdist epdist2, que aceitam muitas funções de distância diferentes, mas não a ponderação. Vi extensões dessas funções que permitem ponderação, mas essas extensões não permitem que os usuários selecionem diferentes funções de distância.
Idealmente, eu gostaria de evitar o uso de funções da caixa de ferramentas estatísticas (não tenho certeza de que o usuário da função terá acesso a essas caixas de ferramentas).
Eu escrevi duas funções para realizar esta tarefa. O primeiro usa chamadas complicadas para repetir e permutar, e o segundo simplesmente usa for-loops.
function [D] = pairdist1(A, B, wts, distancemetric)
% get some information about the data
numA = size(A,1);
numB = size(B,1);
if strcmp(distancemetric,'cityblock')
r=1;
elseif strcmp(distancemetric,'euclidean')
r=2;
else error('Function only accepts "cityblock" and "euclidean" distance')
end
% format weights for multiplication
wts = repmat(wts,[numA,1,numB]);
% get featural differences between A and B pairs
A = repmat(A,[1 1 numB]);
B = repmat(permute(B,[3,2,1]),[numA,1,1]);
differences = abs(A-B).^r;
% weigh difference values before combining them
differences = differences.*wts;
differences = differences.^(1/r);
% combine features to get distance
D = permute(sum(differences,2),[1,3,2]);
end
E:
function [D] = pairdist2(A, B, wts, distancemetric)
% get some information about the data
numA = size(A,1);
numB = size(B,1);
if strcmp(distancemetric,'cityblock')
r=1;
elseif strcmp(distancemetric,'euclidean')
r=2;
else error('Function only accepts "cityblock" and "euclidean" distance')
end
% use for-loops to generate differences
D = zeros(numA,numB);
for i=1:numA
for j=1:numB
differences = abs(A(i,:) - B(j,:)).^(1/r);
differences = differences.*wts;
differences = differences.^(1/r);
D(i,j) = sum(differences,2);
end
end
end
Aqui estão os testes de desempenho:
A = rand(10,3);
B = rand(80,3);
wts = [0.1 0.5 0.4];
distancemetric = 'cityblock';
tic
D1 = pairdist1(A,B,wts,distancemetric);
toc
tic
D2 = pairdist2(A,B,wts,distancemetric);
toc
Elapsed time is 0.000238 seconds.
Elapsed time is 0.005350 seconds.
É claro que a versão repmat-e-permute funciona muito mais rapidamente que a versão double-for-loop, pelo menos para conjuntos de dados menores. Mas eu também sei que as chamadas para repmat muitas vezes atrasam as coisas. Então, eu estou querendo saber se alguém na comunidade SO tem algum conselho a oferecer para melhorar a eficiência de qualquer função!
EDITARO @Luis Mendo ofereceu uma boa limpeza da função repmat-e-permute usandobsxfun. Comparei sua função com o meu original em conjuntos de dados de tamanho variável:
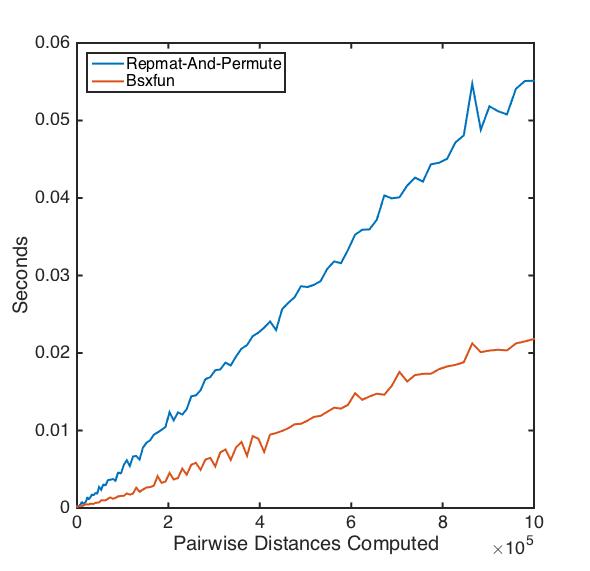
À medida que os dados aumentam, a versão bsxfun se torna o vencedor!
EDIT # 2Eu terminei de escrever a função e ela está disponível no github [ligação] Acabei encontrando um bom método vetorizado para calcular a distância euclidiana [ligação], então eu uso esse método no caso euclidiano e peguei o @ Divakarconselho para quarteirão. Ainda não é tão rápido quanto o pdist2, mas deve ser mais rápido do que qualquer uma das abordagens descritas anteriormente neste post e aceita facilmente ponderações.