У вас все еще есть предсказанные значения около нуля? Вы делали пересчет данных?
аюсь получить опыт работы с Keras во время каникул, и я подумал, что начну с учебного примера прогноза временных рядов на биржевых данных. Итак, что я пытаюсь сделать, учитывая последние 48 часов изменения средней цены (в процентах по сравнению с предыдущим), предсказать, какова средняя цена изменения в наступающем часе.
Однако при проверке по тестовому набору (или даже обучающему набору) амплитуда прогнозируемого ряда отклоняется, а иногда смещается, чтобы быть всегда всегда положительной или всегда отрицательной, т. Е. Сдвигается от изменения 0%, которое я думаю, будет правильным для такого рода вещей.
Я придумал следующий минимальный пример, чтобы показать проблему:
df = pandas.DataFrame.from_csv('test-data-01.csv', header=0)
df['pct'] = df.value.pct_change(periods=1)
seq_len=48
vals = df.pct.values[1:] # First pct change is NaN, skip it
sequences = []
for i in range(0, len(vals) - seq_len):
sx = vals[i:i+seq_len].reshape(seq_len, 1)
sy = vals[i+seq_len]
sequences.append((sx, sy))
row = -24
trainSeqs = sequences[:row]
testSeqs = sequences[row:]
trainX = np.array([i[0] for i in trainSeqs])
trainy = np.array([i[1] for i in trainSeqs])
model = Sequential()
model.add(LSTM(25, batch_input_shape=(1, seq_len, 1)))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(trainX, trainy, epochs=1, batch_size=1, verbose=1, shuffle=True)
pred = []
for s in trainSeqs:
pred.append(model.predict(s[0].reshape(1, seq_len, 1)))
pred = np.array(pred).flatten()
plot(pred)
plot([i[1] for i in trainSeqs])
axis([2500, 2550,-0.03, 0.03])
Как видите, я создаю последовательности обучения и тестирования, выбирая последние 48 часов и следующий шаг в кортеже, а затем продвигаясь вперед на 1 час, повторяя процедуру. Модель представляет собой очень простой 1 LSTM и 1 плотный слой.
Я бы ожидал, что график отдельных предсказанных точек довольно хорошо будет перекрывать график обучающих последовательностей (после всего того же набора, в котором они обучались), и своего рода совпадение для тестовых последовательностей. Однако я получаю следующий результат наданные обучения:
Оранжевый: достоверные данныеСиний: прогнозируемые данные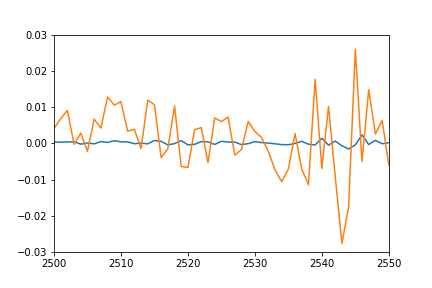
Есть идеи, что может происходить? Я что-то не так понял?
ОбновитьЧтобы лучше показать, что я подразумеваю под сдвинутым и сдавленным, я также нанес на график прогнозируемые значения, сдвинув его обратно, чтобы соответствовать реальным данным, и умножил, чтобы соответствовать амплитуде.
plot(pred*12-0.03)
plot([i[1] for i in trainSeqs])
axis([2500, 2550,-0.03, 0.03])
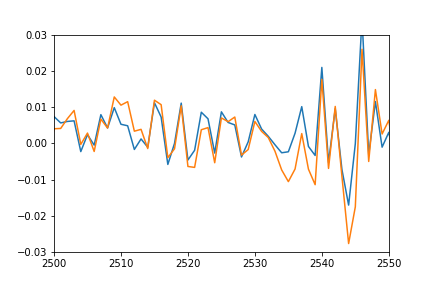
Как вы можете видеть, прогноз хорошо соответствует реальным данным, он просто как-то сдавлен и смещен, и я не могу понять, почему.