Keras LSTM predijo series de tiempo aplastadas y desplazadas
Estoy tratando de obtener experiencia práctica con Keras durante las vacaciones, y pensé que comenzaría con el ejemplo de libro de texto de predicción de series de tiempo sobre datos de existencias. Entonces, lo que intento hacer es dar las últimas 48 horas de cambios en el precio promedio (porcentaje desde el anterior), predecir cuál es el cambio de precio promedio de la próxima hora.
Sin embargo, cuando se verifica contra el conjunto de prueba (o incluso el conjunto de entrenamiento) la amplitud de la serie pronosticada está muy alejada, y a veces se cambia para ser siempre positiva o siempre negativa, es decir, se aleja del cambio del 0%, que yo pensar sería correcto para este tipo de cosas.
Se me ocurrió el siguiente ejemplo mínimo para mostrar el problema:
df = pandas.DataFrame.from_csv('test-data-01.csv', header=0)
df['pct'] = df.value.pct_change(periods=1)
seq_len=48
vals = df.pct.values[1:] # First pct change is NaN, skip it
sequences = []
for i in range(0, len(vals) - seq_len):
sx = vals[i:i+seq_len].reshape(seq_len, 1)
sy = vals[i+seq_len]
sequences.append((sx, sy))
row = -24
trainSeqs = sequences[:row]
testSeqs = sequences[row:]
trainX = np.array([i[0] for i in trainSeqs])
trainy = np.array([i[1] for i in trainSeqs])
model = Sequential()
model.add(LSTM(25, batch_input_shape=(1, seq_len, 1)))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(trainX, trainy, epochs=1, batch_size=1, verbose=1, shuffle=True)
pred = []
for s in trainSeqs:
pred.append(model.predict(s[0].reshape(1, seq_len, 1)))
pred = np.array(pred).flatten()
plot(pred)
plot([i[1] for i in trainSeqs])
axis([2500, 2550,-0.03, 0.03])
Como puede ver, creo secuencias de entrenamiento y pruebas, seleccionando las últimas 48 horas y el siguiente paso hacia una tupla, y luego avanzando 1 hora, repitiendo el procedimiento. El modelo es una capa muy simple de 1 LSTM y 1 densa.
Hubiera esperado que la trama de puntos individuales predichos se superponga bastante bien con la trama de secuencias de entrenamiento (después de todo, este es el mismo conjunto en el que fueron entrenados), y una especie de coincidencia para las secuencias de prueba. Sin embargo obtengo el siguiente resultado endatos de entrenamiento:
Naranja: datos verdaderosAzul: datos pronosticados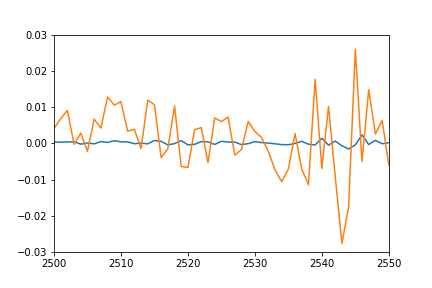
¿Alguna idea de lo que puede estar pasando? ¿Entendí mal algo?
Actualizar: para mostrar mejor lo que quiero decir con desplazado y aplastado, también tracé los valores pronosticados volviéndolo a ajustar para que coincida con los datos reales y multipliqué para que coincida con la amplitud.
plot(pred*12-0.03)
plot([i[1] for i in trainSeqs])
axis([2500, 2550,-0.03, 0.03])
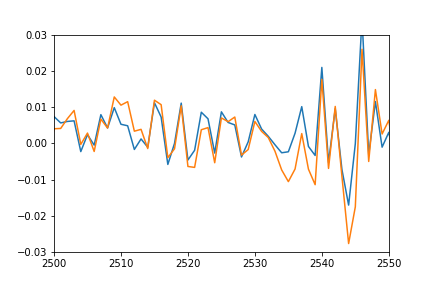
Como puede ver, la predicción se ajusta muy bien a los datos reales, simplemente se aplasta y compensa de alguna manera, y no puedo entender por qué.