, Это даст режим каждой переменной для каждого кластера.
олняю кластерный анализ категориальных данных, поэтому использую подход k-mode.
Мои данные представлены в форме опроса: как вам нравятся волосы и глаза?
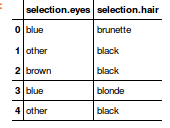
Респондент может получить ответы из фиксированного набора (из нескольких вариантов) из 4 возможных.
Поэтому я получаю манекены, применяю k-моды, присоединяю кластеры обратно к исходному df и затем строю их в 2D с помощью pca.
Мой код выглядит так:
import numpy as np
import pandas as pd
from kmodes import kmodes
df_dummy = pd.get_dummies(df)
#transform into numpy array
x = df_dummy.reset_index().values
km = kmodes.KModes(n_clusters=3, init='Huang', n_init=5, verbose=0)
clusters = km.fit_predict(x)
df_dummy['clusters'] = clusters
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(2)
# Turn the dummified df into two columns with PCA
plot_columns = pca.fit_transform(df_dummy.ix[:,0:12])
# Plot based on the two dimensions, and shade by cluster label
plt.scatter(x=plot_columns[:,1], y=plot_columns[:,0], c=df_dummy["clusters"], s=30)
plt.show()
и я могу визуализировать:
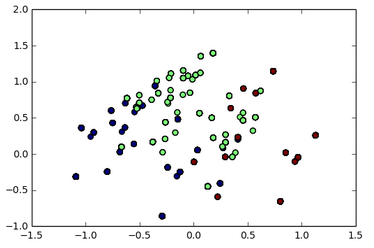
Теперь моя проблема:Можно ли как-то выявить отличительную особенность каждого кластера? то есть каковы основные характеристики (возможно, светлые волосы и голубые глаза) группы зеленых точек на диаграмме рассеяния?
Я понимаю, что кластеризация произошла, но я не могу найти способ перевести, что на самом деле означает кластеризация.
Должен ли я играть с объектом .labels_?