панды объединяют кадры данных на ближайшей отметке времени
Я хочу объединить два кадра данных в трех столбцах: электронная почта, тема и метка времени. Временные метки между фреймами данных различаются, и поэтому мне нужно определить метку наиболее близкого соответствия для группы электронной почты и темы.
Ниже приведен воспроизводимый пример использования функции ближайшего соответствия, предложенной дляэтот вопрос.
import numpy as np
import pandas as pd
from pandas.io.parsers import StringIO
def find_closest_date(timepoint, time_series, add_time_delta_column=True):
# takes a pd.Timestamp() instance and a pd.Series with dates in it
# calcs the delta between `timepoint` and each date in `time_series`
# returns the closest date and optionally the number of days in its time delta
deltas = np.abs(time_series - timepoint)
idx_closest_date = np.argmin(deltas)
res = {"closest_date": time_series.ix[idx_closest_date]}
idx = ['closest_date']
if add_time_delta_column:
res["closest_delta"] = deltas[idx_closest_date]
idx.append('closest_delta')
return pd.Series(res, index=idx)
a = """timestamp,email,subject
2016-07-01 10:17:00,[email protected],subject3
2016-07-01 02:01:02,[email protected],welcome
2016-07-01 14:45:04,[email protected],subject3
2016-07-01 08:14:02,[email protected],subject2
2016-07-01 16:26:35,[email protected],subject4
2016-07-01 10:17:00,[email protected],subject3
2016-07-01 02:01:02,[email protected],welcome
2016-07-01 14:45:04,[email protected],subject3
2016-07-01 08:14:02,[email protected],subject2
2016-07-01 16:26:35,[email protected],subject4
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 02:01:14,[email protected],welcome,1,1
2016-07-01 08:15:48,[email protected],subject2,2,2
2016-07-01 10:17:39,[email protected],subject3,1,7
2016-07-01 14:46:01,[email protected],subject3,1,2
2016-07-01 16:27:28,[email protected],subject4,1,2
2016-07-01 10:17:05,[email protected],subject3,0,0
2016-07-01 02:01:03,[email protected],welcome,0,0
2016-07-01 14:45:05,[email protected],subject3,0,0
2016-07-01 08:16:00,[email protected],subject2,0,0
2016-07-01 17:00:00,[email protected],subject4,0,0
"""
Обратите внимание, что для [email protected] самая близкая совпавшая отметка времени - 10:17:39, тогда как для [email protected] самое близкое совпадение - 10:17:05.
a = """timestamp,email,subject
2016-07-01 10:17:00,[email protected],subject3
2016-07-01 10:17:00,[email protected],subject3
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 10:17:39,[email protected],subject3,1,7
2016-07-01 10:17:05,[email protected],subject3,0,0
"""
df1 = pd.read_csv(StringIO(a), parse_dates=['timestamp'])
df2 = pd.read_csv(StringIO(b), parse_dates=['timestamp'])
df1[['closest', 'time_bt_x_and_y']] = df1.timestamp.apply(find_closest_date, args=[df2.timestamp])
df1
df3 = pd.merge(df1, df2, left_on=['email','subject','closest'], right_on=['email','subject','timestamp'],how='left')
df3
timestamp_x email subject closest time_bt_x_and_y timestamp_y clicks var1
2016-07-01 10:17:00 [email protected] subject3 2016-07-01 10:17:05 00:00:05 NaT NaN NaN
2016-07-01 02:01:02 [email protected] welcome 2016-07-01 02:01:03 00:00:01 NaT NaN NaN
2016-07-01 14:45:04 [email protected] subject3 2016-07-01 14:45:05 00:00:01 NaT NaN NaN
2016-07-01 08:14:02 [email protected] subject2 2016-07-01 08:15:48 00:01:46 2016-07-01 08:15:48 2.0 2.0
2016-07-01 16:26:35 [email protected] subject4 2016-07-01 16:27:28 00:00:53 2016-07-01 16:27:28 1.0 2.0
2016-07-01 10:17:00 [email protected] subject3 2016-07-01 10:17:05 00:00:05 2016-07-01 10:17:05 0.0 0.0
2016-07-01 02:01:02 [email protected] welcome 2016-07-01 02:01:03 00:00:01 2016-07-01 02:01:03 0.0 0.0
2016-07-01 14:45:04 [email protected] subject3 2016-07-01 14:45:05 00:00:01 2016-07-01 14:45:05 0.0 0.0
2016-07-01 08:14:02 [email protected] subject2 2016-07-01 08:15:48 00:01:46 NaT NaN NaN
2016-07-01 16:26:35 [email protected] subject4 2016-07-01 16:27:28 00:00:53 NaT NaN NaN
Результат неверен, главным образом потому, что ближайшая дата неверна, так как не учитывает электронную почту и тему.
Ожидаемый результат
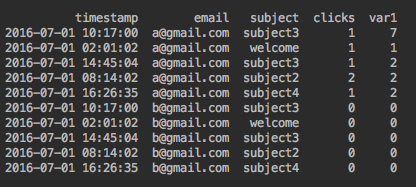
Было бы полезно изменить функцию, чтобы дать самые близкие метки времени для данного письма и темы.
df1.groupby(['email','subject'])['timestamp'].apply(find_closest_date, args=[df1.timestamp])
Но это дает ошибку, так как функция не определена для группового объекта. Какой лучший способ сделать это?