los pandas combinan marcos de datos en la marca de tiempo más cercana
Quiero fusionar dos marcos de datos en tres columnas: correo electrónico, asunto y marca de tiempo. Las marcas de tiempo entre los marcos de datos difieren y, por lo tanto, necesito identificar la marca de tiempo coincidente más cercana para un grupo de correo electrónico y asunto.
A continuación se muestra un ejemplo reproducible que utiliza una función para la coincidencia más cercana sugerida paraesta pregunta.
import numpy as np
import pandas as pd
from pandas.io.parsers import StringIO
def find_closest_date(timepoint, time_series, add_time_delta_column=True):
# takes a pd.Timestamp() instance and a pd.Series with dates in it
# calcs the delta between `timepoint` and each date in `time_series`
# returns the closest date and optionally the number of days in its time delta
deltas = np.abs(time_series - timepoint)
idx_closest_date = np.argmin(deltas)
res = {"closest_date": time_series.ix[idx_closest_date]}
idx = ['closest_date']
if add_time_delta_column:
res["closest_delta"] = deltas[idx_closest_date]
idx.append('closest_delta')
return pd.Series(res, index=idx)
a = """timestamp,email,subject
2016-07-01 10:17:00,[email protected],subject3
2016-07-01 02:01:02,[email protected],welcome
2016-07-01 14:45:04,[email protected],subject3
2016-07-01 08:14:02,[email protected],subject2
2016-07-01 16:26:35,[email protected],subject4
2016-07-01 10:17:00,[email protected],subject3
2016-07-01 02:01:02,[email protected],welcome
2016-07-01 14:45:04,[email protected],subject3
2016-07-01 08:14:02,[email protected],subject2
2016-07-01 16:26:35,[email protected],subject4
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 02:01:14,[email protected],welcome,1,1
2016-07-01 08:15:48,[email protected],subject2,2,2
2016-07-01 10:17:39,[email protected],subject3,1,7
2016-07-01 14:46:01,[email protected],subject3,1,2
2016-07-01 16:27:28,[email protected],subject4,1,2
2016-07-01 10:17:05,[email protected],subject3,0,0
2016-07-01 02:01:03,[email protected],welcome,0,0
2016-07-01 14:45:05,[email protected],subject3,0,0
2016-07-01 08:16:00,[email protected],subject2,0,0
2016-07-01 17:00:00,[email protected],subject4,0,0
"""
Tenga en cuenta que para [email protected] la marca de tiempo coincidente más cercana es 10:17:39, mientras que para [email protected] la coincidencia más cercana es 10:17:05.
a = """timestamp,email,subject
2016-07-01 10:17:00,[email protected],subject3
2016-07-01 10:17:00,[email protected],subject3
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 10:17:39,[email protected],subject3,1,7
2016-07-01 10:17:05,[email protected],subject3,0,0
"""
df1 = pd.read_csv(StringIO(a), parse_dates=['timestamp'])
df2 = pd.read_csv(StringIO(b), parse_dates=['timestamp'])
df1[['closest', 'time_bt_x_and_y']] = df1.timestamp.apply(find_closest_date, args=[df2.timestamp])
df1
df3 = pd.merge(df1, df2, left_on=['email','subject','closest'], right_on=['email','subject','timestamp'],how='left')
df3
timestamp_x email subject closest time_bt_x_and_y timestamp_y clicks var1
2016-07-01 10:17:00 [email protected] subject3 2016-07-01 10:17:05 00:00:05 NaT NaN NaN
2016-07-01 02:01:02 [email protected] welcome 2016-07-01 02:01:03 00:00:01 NaT NaN NaN
2016-07-01 14:45:04 [email protected] subject3 2016-07-01 14:45:05 00:00:01 NaT NaN NaN
2016-07-01 08:14:02 [email protected] subject2 2016-07-01 08:15:48 00:01:46 2016-07-01 08:15:48 2.0 2.0
2016-07-01 16:26:35 [email protected] subject4 2016-07-01 16:27:28 00:00:53 2016-07-01 16:27:28 1.0 2.0
2016-07-01 10:17:00 [email protected] subject3 2016-07-01 10:17:05 00:00:05 2016-07-01 10:17:05 0.0 0.0
2016-07-01 02:01:02 [email protected] welcome 2016-07-01 02:01:03 00:00:01 2016-07-01 02:01:03 0.0 0.0
2016-07-01 14:45:04 [email protected] subject3 2016-07-01 14:45:05 00:00:01 2016-07-01 14:45:05 0.0 0.0
2016-07-01 08:14:02 [email protected] subject2 2016-07-01 08:15:48 00:01:46 NaT NaN NaN
2016-07-01 16:26:35 [email protected] subject4 2016-07-01 16:27:28 00:00:53 NaT NaN NaN
El resultado es incorrecto, principalmente porque la fecha más cercana es incorrecta ya que no tiene en cuenta el correo electrónico y el asunto.
El resultado esperado es
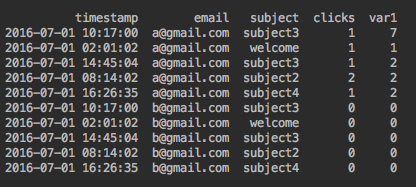
Sería útil modificar la función para proporcionar las marcas de tiempo más cercanas para un correo electrónico y un asunto determinados.
df1.groupby(['email','subject'])['timestamp'].apply(find_closest_date, args=[df1.timestamp])
Pero eso da un error ya que la función no está definida para un objeto de grupo. ¿Cuál es la mejor manera de hacer esto?