Работа с подготовкой данных пакета слов для регрессии
Я пытаюсь создать регрессионную модель, которая предсказывает возраст авторов. Я использую (Нгуен и др., 2011) в качестве моей основы.
Используя модель мешка слов, я считаю количество слов в документе (которые являются сообщениями из досок) и создаю вектор для каждого сообщения.
Я ограничиваю размер каждого вектора, используя в качестве признаков top-k (k = число) наиболее часто используемых слов (не будут использоваться стоп-слова)
Vectorexample_with_k_8 = [0,0,0,1,0,3,0,0]
Мои данные, как правило, редки, как в примере.
Когда я тестирую модель на моих тестовых данных, я получаю очень низкий балл r² (0,00-0,1), иногда даже отрицательный балл. Модель всегда предсказывает один и тот же возраст, который является средним возрастом моего набора данных, как показано в распределении моих данных (возраст / количество):
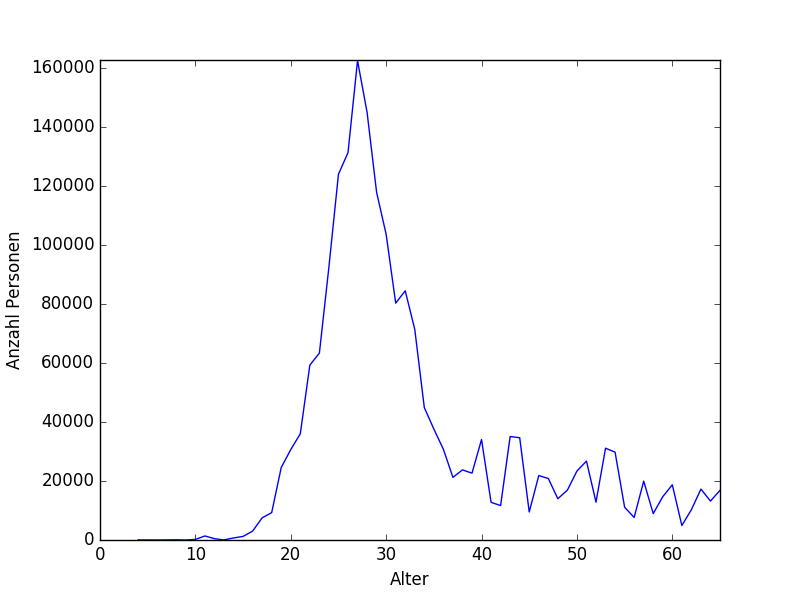
Я использовал разные регрессионные модели: линейная регрессия, лассо, SGDRegressor из scikit-learn без улучшений.
Итак, вопросы:
1.Как я могу улучшить рейтинг?
2. Должен ли я изменить данные для лучшего соответствия регрессии? Если да, то каким способом?
3. Какой регрессор / методы следует использовать для классификации текста?