Как я могу дополнительно оптимизировать запрос производной таблицы, который работает лучше, чем эквивалент JOINed?
UPDATE: Я нашел решение. Смотрите мой ответ ниже.
My QuestionКак я могу оптимизировать этот запрос, чтобы минимизировать время простоя? Мне нужно обновить более 50 схем с количеством билетов от 100 000 до 2 миллионов. Желательно ли попытаться установить все поля в tickets_extra одновременно? Я чувствую, что здесь есть решение, которое я просто не вижу. Я бился головой об эту проблему уже более суток.
Кроме того, я изначально пытался без использования саб SELECT, но производительность былаmuch хуже, чем у меня сейчас.
BackgroundЯ пытаюсь оптимизировать свою базу данных для отчета, который должен быть запущен. Поля, которые мне нужно агрегировать, очень дороги для вычисления, поэтому я денормализую свойсуществующая схема немного, чтобы приспособить этот отчет. Обратите внимание, что я немного упростил таблицу заявок, удалив несколько десятков ненужных столбцов.
Мой отчет будет агрегировать количество билетов поManager When Created а такжеManager When Resolved, Это сложное отношение изображено здесь:
EAV http://cdn.cloudfiles.mosso.com/c163801/eav.png
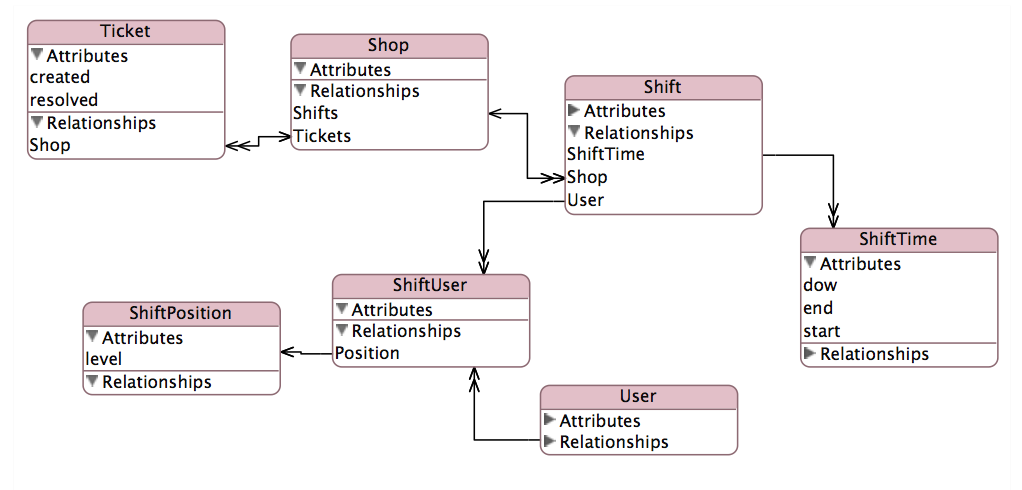{kind=link}
Чтобы избежать полдюжины неприятных объединений, необходимых для вычисления этого «на лету», я добавил следующую таблицу в мою схему:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
Проблема в том, что я нигде не хранил эти данные. Менеджер всегда рассчитывался динамически. я имеюmillions тикетов по нескольким базам данных с одной и той же схемой, которые должны заполнить эту таблицу. Я хочу сделать это настолько эффективным способом, насколько это возможно, но мне не удалось оптимизировать запросы, которые я использую для этого:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
Этот запрос занимает более часа для запуска в схеме, которая имеет & gt; 1,7 миллиона билетов. Это неприемлемо для окна обслуживания, которое у меня есть. Кроме того, он даже не обрабатывает вычисление поля manager_resolved, поскольку попытка объединить его в один и тот же запрос приводит к увеличению времени запроса в стратосфере. Моя текущая склонность состоит в том, чтобы держать их отдельно и использовать UPDATE для заполнения поля manager_resolved, но я не уверен.
Наконец, вот вывод EXPLAIN части SELECT этого запроса:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
Большое спасибо за чтение!