Движок Tesseract OCR не может прочитать текст из автоматически сгенерированного изображения, но может из CUT в MS Paint
используя оболочку .NET для механизма распознавания текста Tesseract. У меня есть большой документ в формате PNG. Когда я вырезаю часть изображения в MS paint и затем подаю его в движок, это работает. Но когда я делаю это в коде, двигатель можетРаспознать текст на изображении. Изображения выглядят одинаково и свойства неПохоже, очень выключен. Так что я'Я немного смущен.
Вот два изображения. Из краски MS:

Из кода:

Это то, что я получаю из изображения краски MS:

И через код:
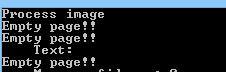
Oни'очень похожи, так что яЯ не уверен, почему это можетне распознаю второй текст. Вот как ям генерации изображения.
public Bitmap CropImage(Bitmap source, Rectangle section)
{
Bitmap bmp = new Bitmap(section.Width, section.Height);
Graphics g = Graphics.FromImage(bmp);
g.DrawImage(source, 0, 0, section, GraphicsUnit.Pixel);
return bmp;
}
private void Form1_Load(object sender, EventArgs e)
{
Bitmap source = new Bitmap(test);
Rectangle section = new Rectangle(new Point(78, 65), new Size(800, 50));
Bitmap CroppedImage = CropImage(source, section);
CroppedImage.Save(@"c:\users\user\desktop\test34.png", System.Drawing.Imaging.ImageFormat.Png);
this.pictureBox1.Image = CroppedImage;
}