Não é possível se livrar de linhas em branco na saída csv
Eu escrevi um script muito pequeno em python scrapy para analisar o nome, a rua e o número de telefone exibidos em várias páginas do site da página amarela. Quando executo meu script, acho que ele funciona sem problemas. No entanto, o único problema que encontro é a maneira como os dados são raspados na saída csv. É sempre um intervalo de linha (linha) entre duas linhas. O que eu quis dizer é: os dados estão sendo impressos em todas as outras linhas. Ao ver a figura abaixo, você saberá o que eu quis dizer. Se não fosse por scrapy, eu poderia ter usado [newline = '']. Mas, infelizmente, estou totalmente desamparado aqui. Como posso me livrar das linhas em branco que aparecem na saída csv? Agradecemos antecipadamente a dar uma olhada nele.
items.py inclui:
import scrapy
class YellowpageItem(scrapy.Item):
name = scrapy.Field()
street = scrapy.Field()
phone = scrapy.Field()
Aqui está a aranha:
import scrapy
class YellowpageSpider(scrapy.Spider):
name = "YellowpageSp"
start_urls = ["https://www.yellowpages.com/search?search_terms=Pizza&geo_location_terms=Los%20Angeles%2C%20CA&page={0}".format(page) for page in range(2,6)]
def parse(self, response):
for titles in response.css('div.info'):
name = titles.css('a.business-name span[itemprop=name]::text').extract_first()
street = titles.css('span.street-address::text').extract_first()
phone = titles.css('div[itemprop=telephone]::text').extract_first()
yield {'name': name, 'street': street, 'phone':phone}
Aqui está como a saída csv se parece:
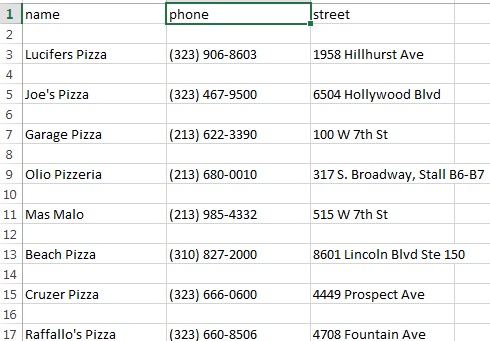
Btw, o comando que estou usando para obter a saída csv é:
scrapy crawl YellowpageSp -o items.csv -t csv