@ Шахин, да, это правильное поведение, так как скрапинг не имеет никаких настроек для порядка полей. Вам нужно будет настроить этот экспортер для достижения того же
исал очень крошечный скрипт в Python Scrapy, чтобы разобрать имя, улицу и номер телефона, отображаемые на нескольких страницах с сайта желтой страницы. Когда я запускаю свой скрипт, я нахожу, что он работает гладко. Тем не менее, единственная проблема, с которой я сталкиваюсь - это способ очистки данных в выводе csv. Это всегда разрыв строки (строки) между двумя рядами. Я имел в виду следующее: данные печатаются в каждой строке. Увидев картинку ниже, вы поймете, что я имел в виду. Если бы не скрап, я бы использовал [newline = '']. Но, к сожалению, я здесь совершенно беспомощен. Как я могу избавиться от пустых строк, появляющихся в выводе CSV? Спасибо заранее, чтобы взглянуть на это.
items.py включает в себя:
import scrapy
class YellowpageItem(scrapy.Item):
name = scrapy.Field()
street = scrapy.Field()
phone = scrapy.Field()
Вот паук:
import scrapy
class YellowpageSpider(scrapy.Spider):
name = "YellowpageSp"
start_urls = ["https://www.yellowpages.com/search?search_terms=Pizza&geo_location_terms=Los%20Angeles%2C%20CA&page={0}".format(page) for page in range(2,6)]
def parse(self, response):
for titles in response.css('div.info'):
name = titles.css('a.business-name span[itemprop=name]::text').extract_first()
street = titles.css('span.street-address::text').extract_first()
phone = titles.css('div[itemprop=telephone]::text').extract_first()
yield {'name': name, 'street': street, 'phone':phone}
Вот как выглядит вывод csv:
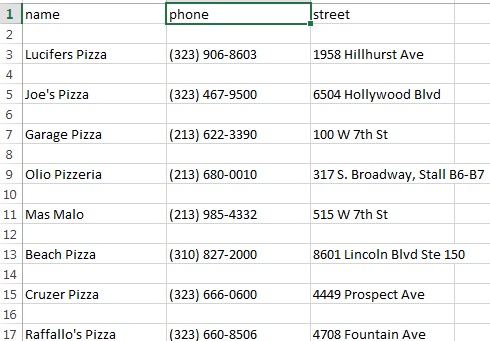
Кстати, команда, которую я использую, чтобы получить вывод CSV:
scrapy crawl YellowpageSp -o items.csv -t csv