Trabalhando com, preparando dados detalhados para Regressão
Estou tentando criar um modelo de regressão que prevê a idade de um autor. Estou usando (Nguyen et al, 2011) como minha base.
Usando um modelo de saco de palavras, conto as ocorrências de palavras por documento (que são postagens de painéis) e crio o vetor para cada post.
Limito o tamanho de cada vetor usando como recursos as palavras mais usadas entre os top-k (k = número) (as palavras de parada não serão usadas)
Vectorexample_with_k_8 = [0,0,0,1,0,3,0,0]
Meus dados são geralmente escassos, como no exemplo.
Quando testei o modelo nos meus dados de teste, obtive uma pontuação r² muito baixa (0,00-0,1), às vezes até uma pontuação negativa. O modelo prediz sempre a mesma idade, que é a idade média do meu conjunto de dados, como visto na distribuição dos meus dados (idade / quantidade):
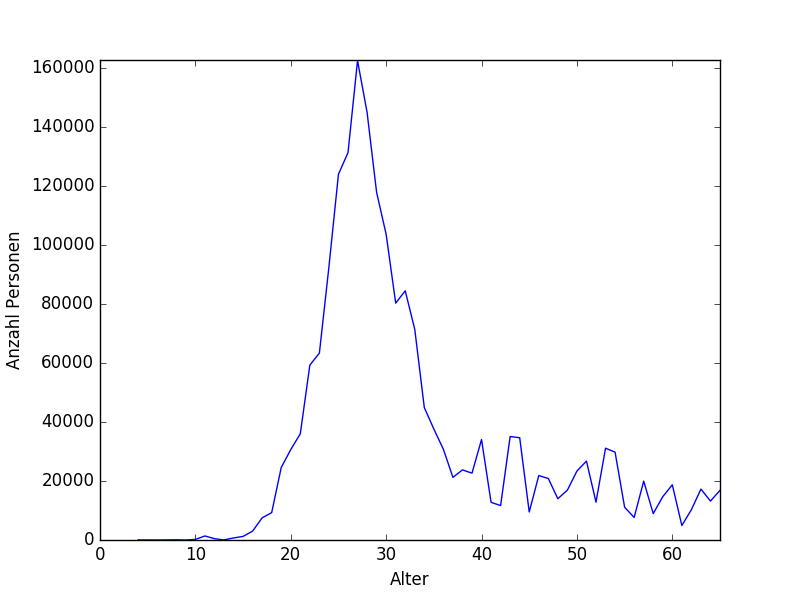
Eu usei diferentes modelos de regressão: regressão linear, laço, SGDRegressor do scikit-learn sem melhoria.
Então, as perguntas são:
1.Como melhoro a pontuação r²?
2.Tenho que alterar os dados para ajustar melhor a regressão? Se sim, com qual método?
3.Qual regressor / métodos devo usar para a classificação do texto?