¿Por qué el texto gujarati-indio no se representa correctamente con Arial Unicode MS?
Este es un seguimiento de esta pregunta¿Cómo exportar fuentes en idioma gujarati-indio a pdf?, @ amedee-van-gasse, Ingeniero de control de calidad en iTextPregúntame para publicar una pregunta específica para itext con mcve relevante.
¿Por qué es esta secuencia de Unicode?\u0ab9\u0abf\u0aaa\u0acd\u0ab8 no se procesa correctamente?
Debería representarse así:
હિપ્સ, también probado conconvertidor unicode
sin embargoeste codigo (ejemplo de forma adaptadaiText: Capítulo 11: Elegir la fuente correcta)
public class FontTest {
/** The resulting PDF file. */
public static final String RESULT = "fontTest.pdf";
/** the text to render. */
public static final String TEST = "\u0ab9\u0abf\u0aaa\u0acd\u0ab8";
public void createPdf(String filename) throws IOException, DocumentException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(filename));
document.open();
BaseFont bf = BaseFont.createFont(
"ARIALUNI.TTF", BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
Font font = new Font(bf, 20);
ColumnText column = new ColumnText(writer.getDirectContent());
column.setSimpleColumn(36, 730, 569, 36);
column.addElement(new Paragraph(TEST, font));
column.go();
document.close();
System.out.println("DONE");
}
public static void main(String[] args) throws IOException, DocumentException {
new FontTest().createPdf(RESULT);
}
}
Genera estoresultado:
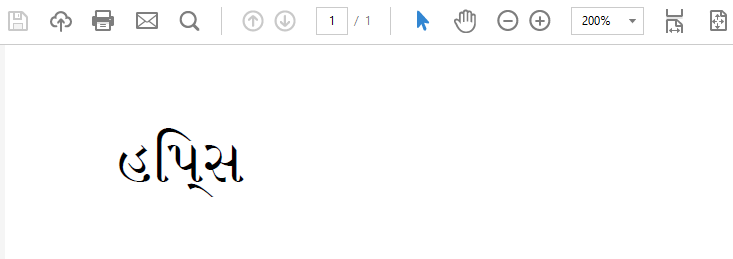
Eso se ve diferente de
હિપ્સ
Tengo prueba conitextpdf-5.5.4.jar,itextpdf-5.5.9.jar y tambiénitext-2.1.7.js3.jar (distribuido con informes jasper)
La fuente utilizada es la que distribuye con MS OfficeARIALUNI.TTF y se puede descargar desde aquíArial Unicode MS * Quizás haya algunos problemas legales al descargar ver el comentario de Mike 'Pomax' Kamermans