k означает алгоритм кластеризации
Я хочу выполнить кластерный анализ k средних для набора из 10 точек данных, каждый из которых имеет массив из 4 числовых значений, связанных с ними. Я'м, используя коэффициент корреляции Пирсона в качестве метрики расстояния. Я сделал первые два шага алгоритма кластеризации k средних:
1) Выберите набор начальных центров из k кластеров. [Я выбрал два начальных центра наугад]
2) Назначьте каждый объект кластеру с ближайшим центром. [Я использовал коэффициент корреляции Пирсона в качестве метрики расстояния - см. Ниже]
Теперь мне нужна помощь в понимании 3-го шага в алгоритме:
3) Вычислить новые центры кластеров:
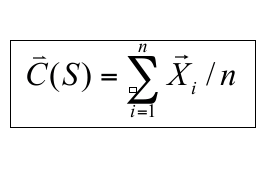

где X в данном случае - четырехмерный вектор, а n - количество точек данных в кластере.
Как мне рассчитать C (S) для следующих данных?
# Cluster 1
A 10 15 20 25 # randomly chosen centre
B 21 33 21 23
C 43 14 23 23
D 37 45 43 49
E 40 43 32 32
# Cluster 2
F 100 102 143 212 #random chosen centre
G 303 213 212 302
H 102 329 203 212
I 32 201 430 48
J 60 99 87 34
Последний шаг алгоритма k означает повторение шагов 2 и 3, пока ни один объект не изменит кластер, что достаточно просто.
Мне нужна помощь с шагом 3. Вычисление новых центров кластеров. Если бы кто-то мог пройти и объяснить, как вычислить новый центр только одного из кластеров, это мне очень помогло бы.