Производительность умножения матриц Фортрана при различной оптимизации
я читаю книгуНаучная разработка программного обеспечения с Фортран "И в этом есть упражнение, которое я считаю очень интересным:
Создайте модуль Fortran с именем MatrixMultiplyModule. Добавьте к нему три подпрограммы: LoopMatrixMultiply, IntrinsicMatrixMultiply и MixMatrixMultiply. Каждая подпрограмма должна принимать две действительные матрицы в качестве аргумента, выполнять умножение матриц и возвращать результат через третий аргумент. LoopMatrixMultiply должен быть написан целиком с циклами do, без операций с массивами или встроенных процедур; IntrinsicMatrixMultiply должен быть написан с использованием встроенной функции matmul; и MixMatrixMultiply должен быть написан с использованием некоторых циклов do и встроенной функции dot_product. Напишите небольшую программу для проверки производительности этих трех различных способов выполнения умножения матриц для матриц разных размеров ».
Я сделал несколько тестов умножения матрицы 2 ранга 2, и вот результаты под разными флагами оптимизации:
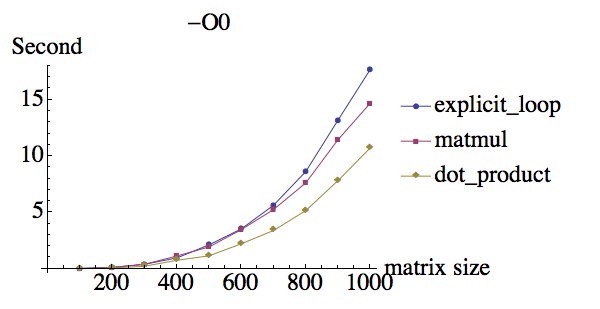
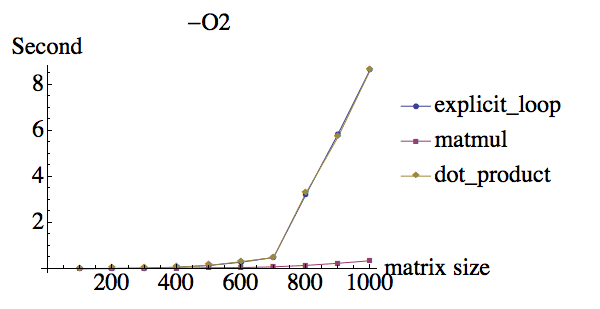

compiler:ifort version 13.0.0 on Mac
Вот мой вопрос:
Почему при -O0 они имеют примерно одинаковую производительность, но у matmul огромный прирост производительности при использовании -O3, в то время как явные циклические и точечные продукты имеют меньшее повышение производительности? Кроме того, почему у dot_product такая же производительность по сравнению с явными циклами do?
Я использую следующий код:
module MatrixMultiplyModule
contains
subroutine LoopMatrixMultiply(mtx1,mtx2,mtx3)
real,intent(in) :: mtx1(:,:),mtx2(:,:)
real,intent(out),allocatable :: mtx3(:,:)
integer :: m,n
integer :: i,j
if(size(mtx1,dim=2) /= size(mtx2,dim=1)) stop "input array size not match"
m=size(mtx1,dim=1)
n=size(mtx2,dim=2)
allocate(mtx3(m,n))
mtx3=0.
do i=1,m
do j=1,n
do k=1,size(mtx1,dim=2)
mtx3(i,j)=mtx3(i,j)+mtx1(i,k)*mtx2(k,j)
end do
end do
end do
end subroutine
subroutine IntrinsicMatrixMultiply(mtx1,mtx2,mtx3)
real,intent(in) :: mtx1(:,:),mtx2(:,:)
real,intent(out),allocatable :: mtx3(:,:)
integer :: m,n
integer :: i,j
if(size(mtx1,dim=2) /= size(mtx2,dim=1)) stop "input array size not match"
m=size(mtx1,dim=1)
n=size(mtx2,dim=2)
allocate(mtx3(m,n))
mtx3=matmul(mtx1,mtx2)
end subroutine
subroutine MixMatrixMultiply(mtx1,mtx2,mtx3)
real,intent(in) :: mtx1(:,:),mtx2(:,:)
real,intent(out),allocatable :: mtx3(:,:)
integer :: m,n
integer :: i,j
if(size(mtx1,dim=2) /= size(mtx2,dim=1)) stop "input array size not match"
m=size(mtx1,dim=1)
n=size(mtx2,dim=2)
allocate(mtx3(m,n))
do i=1,m
do j=1,n
mtx3(i,j)=dot_product(mtx1(i,:),mtx2(:,j))
end do
end do
end subroutine
end module
program main
use MatrixMultiplyModule
implicit none
real,allocatable :: a(:,:),b(:,:)
real,allocatable :: c1(:,:),c2(:,:),c3(:,:)
integer :: n
integer :: count, rate
real :: timeAtStart, timeAtEnd
real :: time(3,10)
do n=100,1000,100
allocate(a(n,n),b(n,n))
call random_number(a)
call random_number(b)
call system_clock(count = count, count_rate = rate)
timeAtStart = count / real(rate)
call LoopMatrixMultiply(a,b,c1)
call system_clock(count = count, count_rate = rate)
timeAtEnd = count / real(rate)
time(1,n/100)=timeAtEnd-timeAtStart
call system_clock(count = count, count_rate = rate)
timeAtStart = count / real(rate)
call IntrinsicMatrixMultiply(a,b,c2)
call system_clock(count = count, count_rate = rate)
timeAtEnd = count / real(rate)
time(2,n/100)=timeAtEnd-timeAtStart
call system_clock(count = count, count_rate = rate)
timeAtStart = count / real(rate)
call MixMatrixMultiply(a,b,c3)
call system_clock(count = count, count_rate = rate)
timeAtEnd = count / real(rate)
time(3,n/100)=timeAtEnd-timeAtStart
deallocate(a,b)
end do
open(1,file="time.txt")
do n=1,10
write(1,*) time(:,n)
end do
close(1)
deallocate(c1,c2,c3)
end program