Распознавание символов (алгоритм OCR) [закрыто]
Я работаю над проектом, в котором мне нужно разработать алгоритм распознавания текста (я должен прочитать текст из Image, а затем преобразовать его на другой язык). Поэтому моя первая задача - получить текст из изображения.
Шаги для завершения первого задания.
Загрузка любого формата изображения (BMP, JPG, PNG) из указанного источника. Затем преобразуйте изображение в оттенки серого и оцифруйте его, используя пороговое значение (алгоритм Оцу). // завершено (Как убрать шум из выходного изображения ???)Результаты
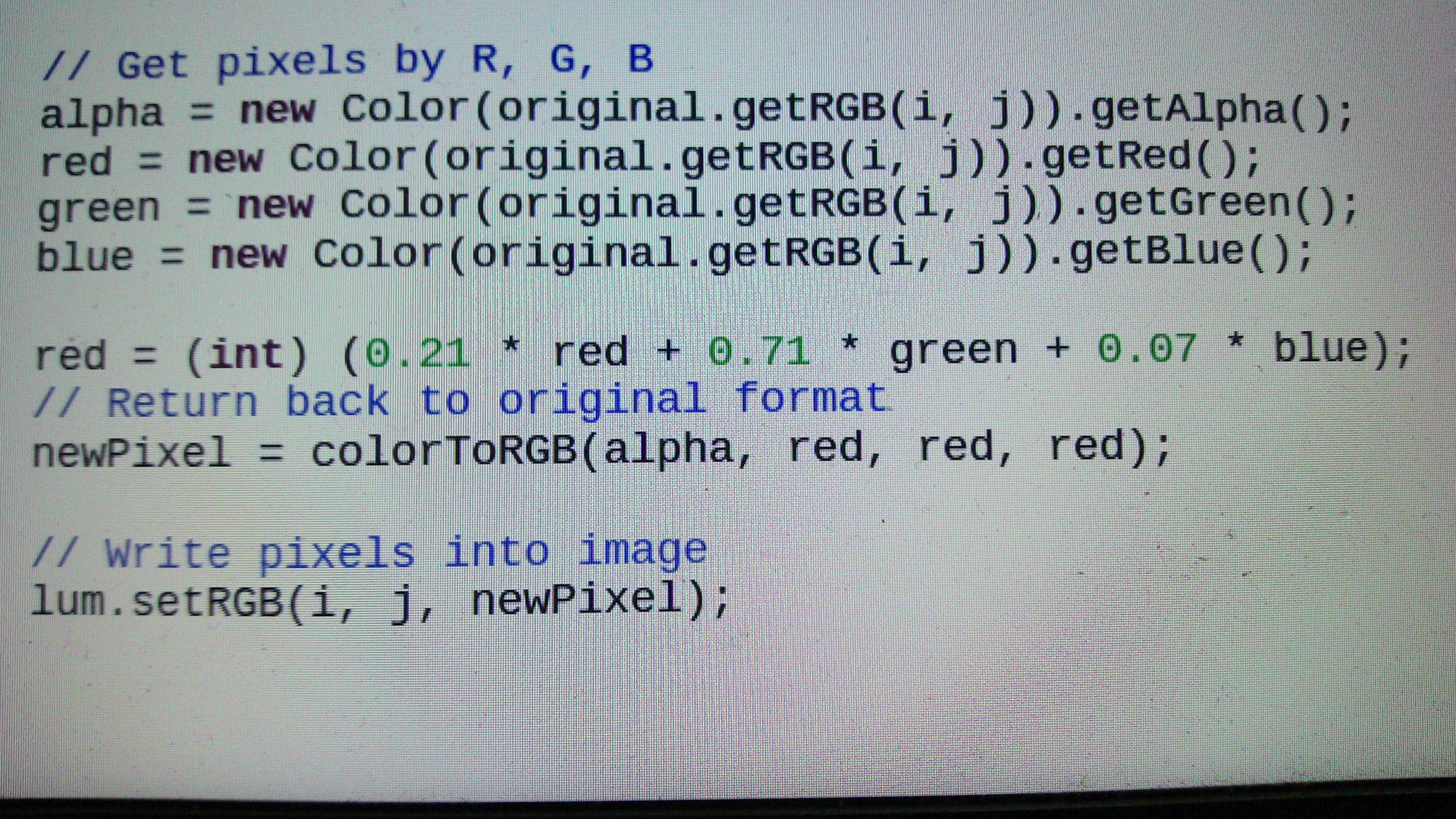
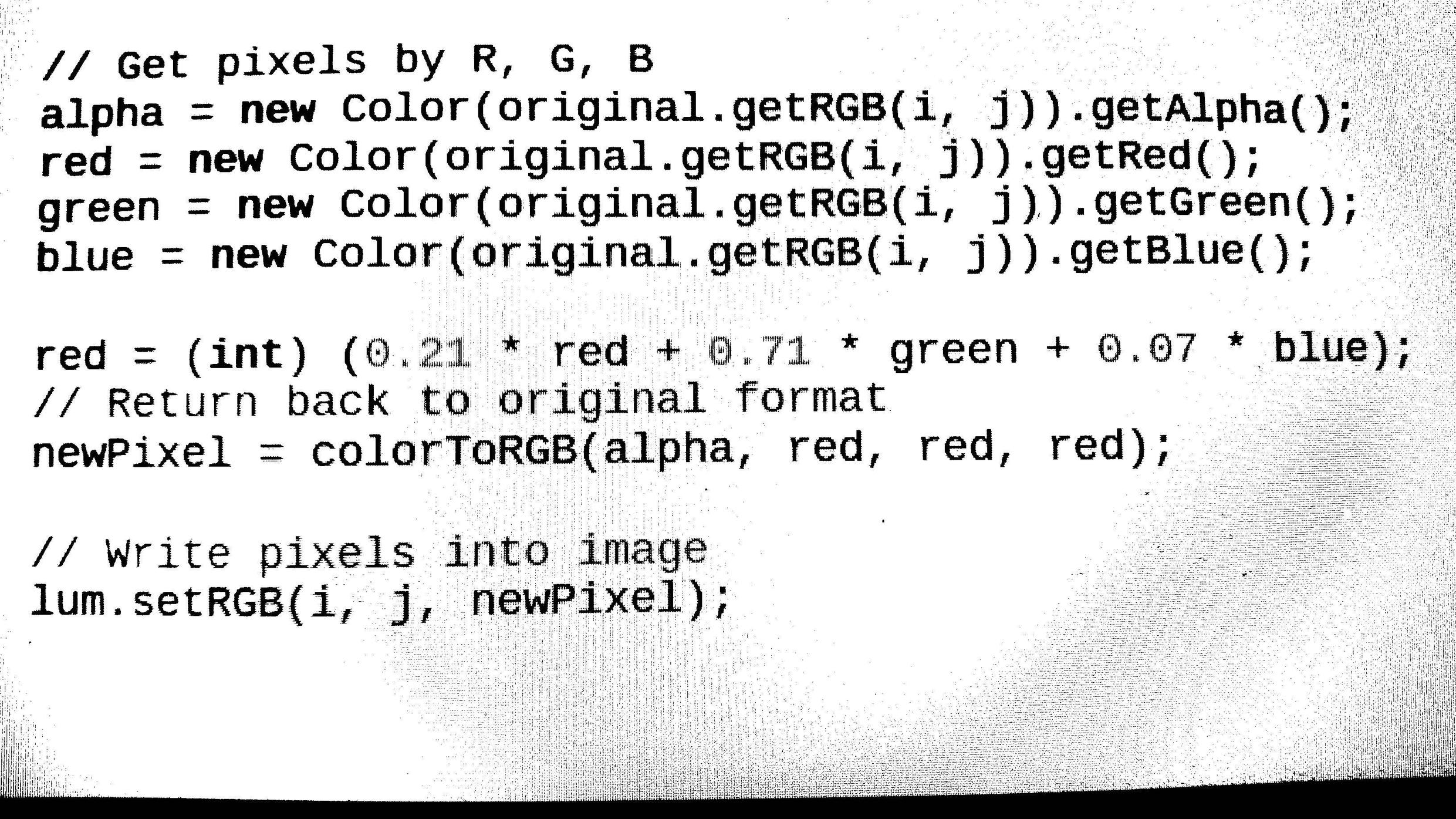
Обнаружение функций изображения, таких как разрешение и инверсия. Так что мы можем наконец преобразовать его в выпрямленное изображение для дальнейшей обработки. (завершил код поворота изображения, но не смог определить угол изображения, на который мы должны повернуть изображение, поэтому все еще работаем над частью определения угла)
Линии обнаружения и удаления. Этот шаг необходим для улучшения анализа макета страницы, повышения качества распознавания подчеркнутого текста, обнаружения таблиц и т. Д. (Решено завершить эту часть в конце)
Анализ макета страницы. На этом этапе я пытаюсь определить текстовые зоны, присутствующие на изображении. Так что только эта часть используется для распознавания, а остальная часть региона не учитывается.
Обнаружение текстовых строк и слов. Здесь мы также должны позаботиться о разном размере шрифта и небольшом расстоянии между словами.
Распознавание персонажей. Это основной алгоритм OCR; изображение каждого символа должно быть преобразовано в соответствующий код символа. Иногда этот алгоритм выдает несколько кодов символов для неопределенных изображений. Например, распознавание образа «я» персонаж может производить «Я», «|» «1», «l» коды и окончательный код символа будут выбраны позже.
Сохранение результатов в выбранном формате вывода, например, с возможностью поиска PDF, DOC, RTF, TXT. Важно сохранить оригинальный макет страницы: столбцы, шрифты, цвета, картинки, фон и так далее.
Поэтому мне нужна помощь в части 6. Я завершил часть обнаружения строк (получаю n изображений из абзаца, содержащего n строк), но застрял в следующей части, получая слова и распознавание символов. Если вы знаете хорошие ссылки, связанные с частью распознавания и распознавания символов, пожалуйста, напишите Вот.
Для распознавания символов я думаю использовать asprise (библиотека Java)http://asprise.com/product/ocr/index.php?lang=java