Верхний график показывает исходную линейную функцию и некоторые данные, полученные из нее с использованием асимметричных гауссовых ошибок. Построены столбцы ошибок, а также кусочные эллипсы ошибок (серые ... и масштабированные до касания линейной функции, синие). Нижний график дополнительно показывает установленную функцию, а также масштабированные кусочные эллипсы, которые касаются установленной функции.
аюсь приспособить некоторые данные к степенному закону, используя python. Проблема в том, что некоторые из моих пунктов - это верхние пределы, которые я не знаю, как включить в примерку.
В данных я поместил верхние пределы как ошибки в y, равные 1, когда остальное намного меньше. Вы можете установить эти ошибки на 0 и изменить генератор списка uplims, но тогда совпадение будет ужасным.
Код следующий:
import numpy as np
import matplotlib.pyplot as plt
from scipy.odr import *
# Initiate some data
x = [1.73e-04, 5.21e-04, 1.57e-03, 4.71e-03, 1.41e-02, 4.25e-02, 1.28e-01, 3.84e-01, 1.15e+00]
x_err = [1e-04, 1e-04, 1e-03, 1e-03, 1e-02, 1e-02, 1e-01, 1e-01, 1e-01]
y = [1.26e-05, 8.48e-07, 2.09e-08, 4.11e-09, 8.22e-10, 2.61e-10, 4.46e-11, 1.02e-11, 3.98e-12]
y_err = [1, 1, 2.06e-08, 2.5e-09, 5.21e-10, 1.38e-10, 3.21e-11, 1, 1]
# Define upper limits
uplims = np.ones(len(y_err),dtype='bool')
for i in range(len(y_err)):
if y_err[i]<1:
uplims[i]=0
else:
uplims[i]=1
# Define a function (power law in our case) to fit the data with.
def function(p, x):
m, c = p
return m*x**(-c)
# Create a model for fitting.
model = Model(function)
# Create a RealData object using our initiated data from above.
data = RealData(x, y, sx=x_err, sy=y_err)
# Set up ODR with the model and data.
odr = ODR(data, model, beta0=[1e-09, 2])
odr.set_job(fit_type=0) # 0 is full ODR and 2 is least squares; AFAIK, it doesn't change within errors
# more details in https://docs.scipy.org/doc/scipy/reference/generated/scipy.odr.ODR.set_job.html
# Run the regression.
out = odr.run()
# Use the in-built pprint method to give us results.
#out.pprint() #this prints much information, but normally we don't need it, just the parameters and errors; the residual variation is the reduced chi square estimator
print('amplitude = %5.2e +/- %5.2e \nindex = %5.2f +/- %5.2f \nchi square = %12.8f'% (out.beta[0], out.sd_beta[0], out.beta[1], out.sd_beta[1], out.res_var))
# Generate fitted data.
x_fit = np.linspace(x[0], x[-1], 1000) #to do the fit only within the x interval; we can always extrapolate it, of course
y_fit = function(out.beta, x_fit)
# Generate a plot to show the data, errors, and fit.
fig, ax = plt.subplots()
ax.errorbar(x, y, xerr=x_err, yerr=y_err, uplims=uplims, linestyle='None', marker='x')
ax.loglog(x_fit, y_fit)
ax.set_xlabel(r'$xРезультат подгонки:
amplitude = 3.42e-12 +/- 5.32e-13
index = 1.33 +/- 0.04
chi square = 0.01484021
![]()
Как вы можете видеть на графике, две первые и две последние точки являются верхними пределами, и подгонка не учитывает их. Более того, в предпоследней точке подгонка проходит через это, хотя это будет строго запрещено.
Мне нужно, чтобы подгонка знала, что эти пределы очень строги, и не пытаюсь соответствовать самой точке, а только рассматриваю их как пределы. Как я мог бы сделать это с помощью подпрограммы odr (или любого другого кода, который делает меня подходящим и дает мне оценку ци квадратного esque)?
Пожалуйста, примите во внимание, что мне нужно легко изменить функцию на другие обобщения, поэтому такие вещи, как модуль powerlaw, нежелательны.
Спасибо!
)
ax.set_ylabel(r'$f(x) = m·x^{-c}Результат подгонки:
amplitude = 3.42e-12 +/- 5.32e-13
index = 1.33 +/- 0.04
chi square = 0.01484021
![]()
Как вы можете видеть на графике, две первые и две последние точки являются верхними пределами, и подгонка не учитывает их. Более того, в предпоследней точке подгонка проходит через это, хотя это будет строго запрещено.
Мне нужно, чтобы подгонка знала, что эти пределы очень строги, и не пытаюсь соответствовать самой точке, а только рассматриваю их как пределы. Как я мог бы сделать это с помощью подпрограммы odr (или любого другого кода, который делает меня подходящим и дает мне оценку ци квадратного esque)?
Пожалуйста, примите во внимание, что мне нужно легко изменить функцию на другие обобщения, поэтому такие вещи, как модуль powerlaw, нежелательны.
Спасибо!
)
ax.set_title('Power Law fit')
plt.show()
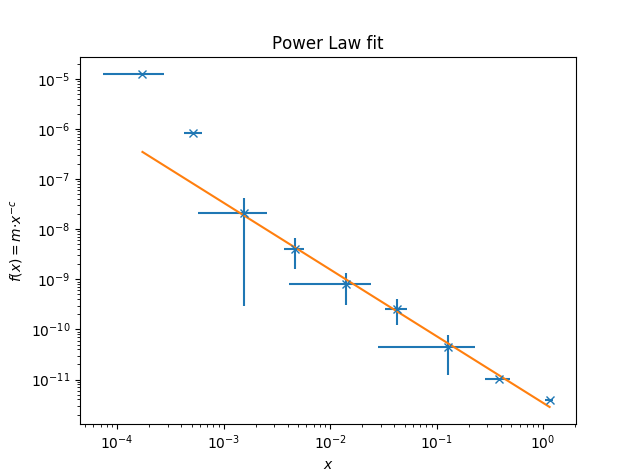
Результат подгонки:
amplitude = 3.42e-12 +/- 5.32e-13
index = 1.33 +/- 0.04
chi square = 0.01484021
Как вы можете видеть на графике, две первые и две последние точки являются верхними пределами, и подгонка не учитывает их. Более того, в предпоследней точке подгонка проходит через это, хотя это будет строго запрещено.
Мне нужно, чтобы подгонка знала, что эти пределы очень строги, и не пытаюсь соответствовать самой точке, а только рассматриваю их как пределы. Как я мог бы сделать это с помощью подпрограммы odr (или любого другого кода, который делает меня подходящим и дает мне оценку ци квадратного esque)?
Пожалуйста, примите во внимание, что мне нужно легко изменить функцию на другие обобщения, поэтому такие вещи, как модуль powerlaw, нежелательны.
Спасибо!