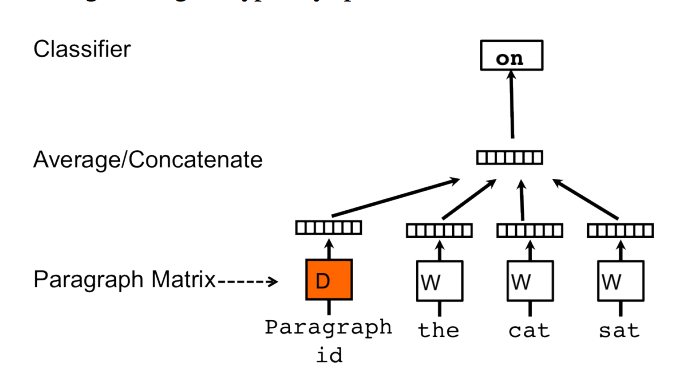
Как gensim вычисляет векторы абзаца doc2vec
я иду через эту статьюhttp://cs.stanford.edu/~quocle/paragraph_vector.pdf
и говорится, что
«Вектор параграфа и векторы слова усредняются или объединяются, чтобы предсказать следующее слово в контексте. В экспериментах мы используем конкатенацию как метод объединения векторов».
Как работает конкатенация или усреднение?
пример (если абзац 1 содержит слова 1 и 2):
word1 vector =[0.1,0.2,0.3]
word2 vector =[0.4,0.5,0.6]
concat method
does paragraph vector = [0.1+0.4,0.2+0.5,0.3+0.6] ?
Average method
does paragraph vector = [(0.1+0.4)/2,(0.2+0.5)/2,(0.3+0.6)/2] ?
Также из этого изображения:
Заявлено, что:
Маркер абзаца можно представить как другое слово. Он действует как память, которая запоминает то, чего не хватает в текущем контексте или в теме абзаца. По этой причине мы часто называем эту модель моделью распределенной памяти векторов абзацев (PV-DM).
Токен абзаца равен вектору абзаца, который равенon?