¿Cómo calcula gensim los vectores de párrafo doc2vec?
voy a seguir este papelhttp://cs.stanford.edu/~quocle/paragraph_vector.pdf
y dice que
"El vector de párrafo y los vectores de palabras se promedian o concatenan para predecir la siguiente palabra en un contexto. En los experimentos, utilizamos la concatenación como método para combinar los vectores".
¿Cómo funciona la concatenación o el promedio?
ejemplo (si el párrafo 1 contiene word1 y word2):
word1 vector =[0.1,0.2,0.3]
word2 vector =[0.4,0.5,0.6]
concat method
does paragraph vector = [0.1+0.4,0.2+0.5,0.3+0.6] ?
Average method
does paragraph vector = [(0.1+0.4)/2,(0.2+0.5)/2,(0.3+0.6)/2] ?
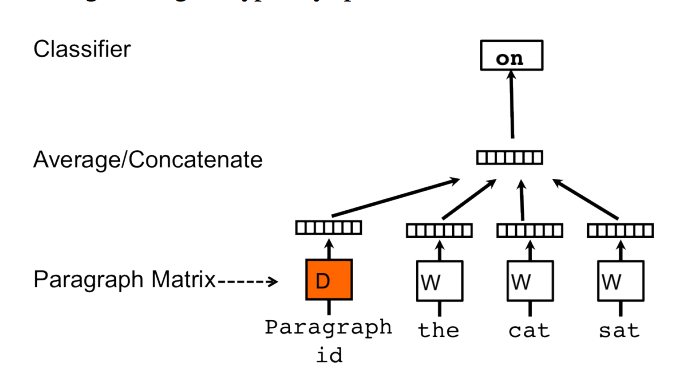
También de esta imagen:
Se indica que :
El token de párrafo puede considerarse como otra palabra. Actúa como un recuerdo que recuerda lo que falta en el contexto actual, o el tema del párrafo. Por esta razón, a menudo llamamos a este modelo el Modelo de memoria distribuida de vectores de párrafo (PV-DM).
¿Es el token de párrafo igual al vector de párrafo que es igual aon?