KMeans Spark не в состоянии обрабатывать большие данные?
KMeans имеет несколько параметров для егоповышение квалификации, с режимом инициализации по умолчанию kmeans ||. Проблема в том, что он быстро (менее 10 минут) идет к первым 13 этапам, но затемвиснет полностьюбез ошибки!
Минимальный пример который воспроизводит проблему (это будет успешно, если я использую 1000 точек или случайную инициализацию):
from pyspark.context import SparkContext
from pyspark.mllib.clustering import KMeans
from pyspark.mllib.random import RandomRDDs
if __name__ == "__main__":
sc = SparkContext(appName='kmeansMinimalExample')
# same with 10000 points
data = RandomRDDs.uniformVectorRDD(sc, 10000000, 64)
C = KMeans.train(data, 8192, maxIterations=10)
sc.stop()
Задание ничего не делает (оно не удается, не удается или не выполняется ..), как показано ниже. На вкладке «Исполнители» нет активных / не выполненных задач. В журналах Stdout и Stderr нет ничего особенно интересного:
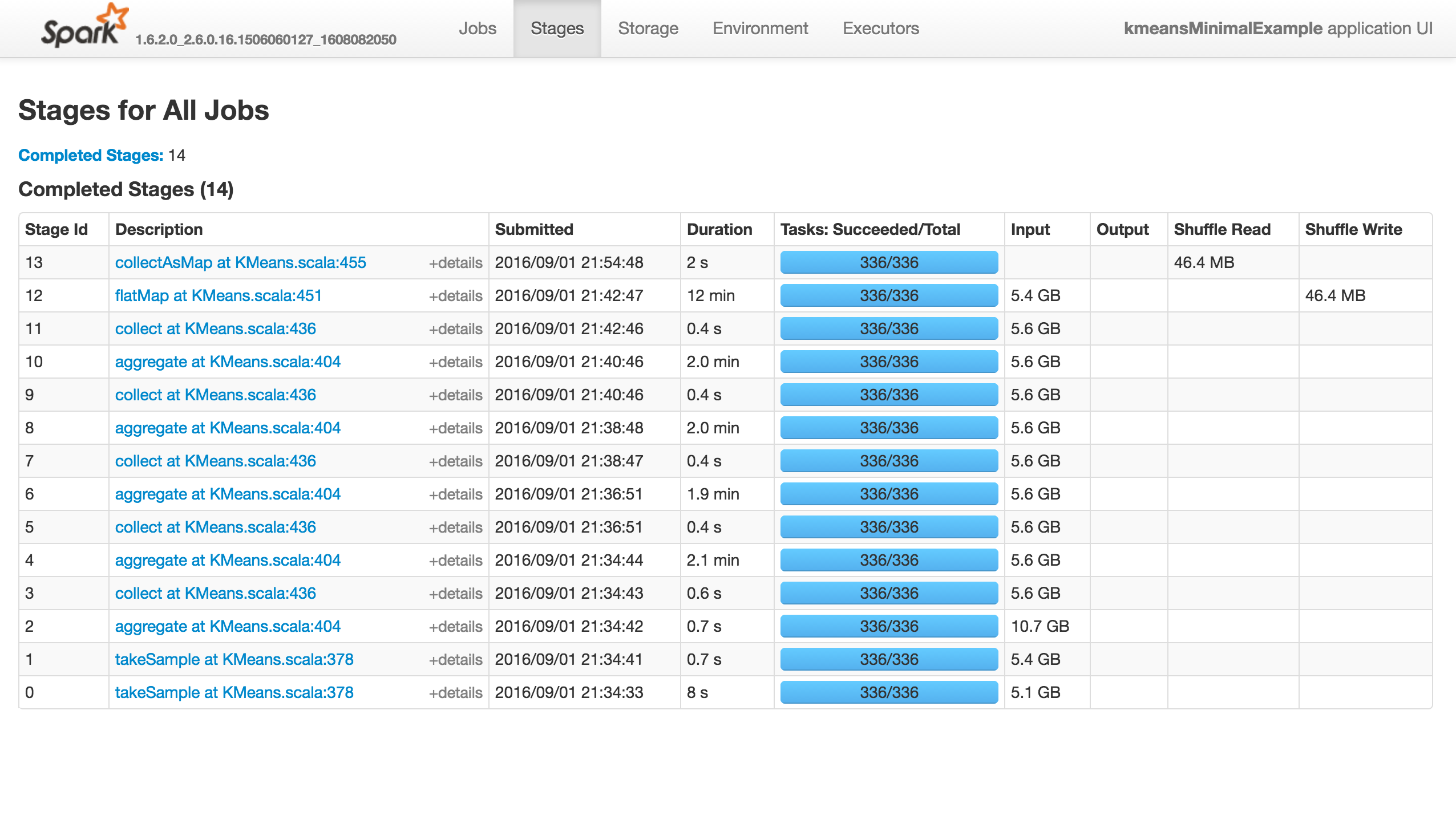
Если я используюk=81вместо 8192 это получится:
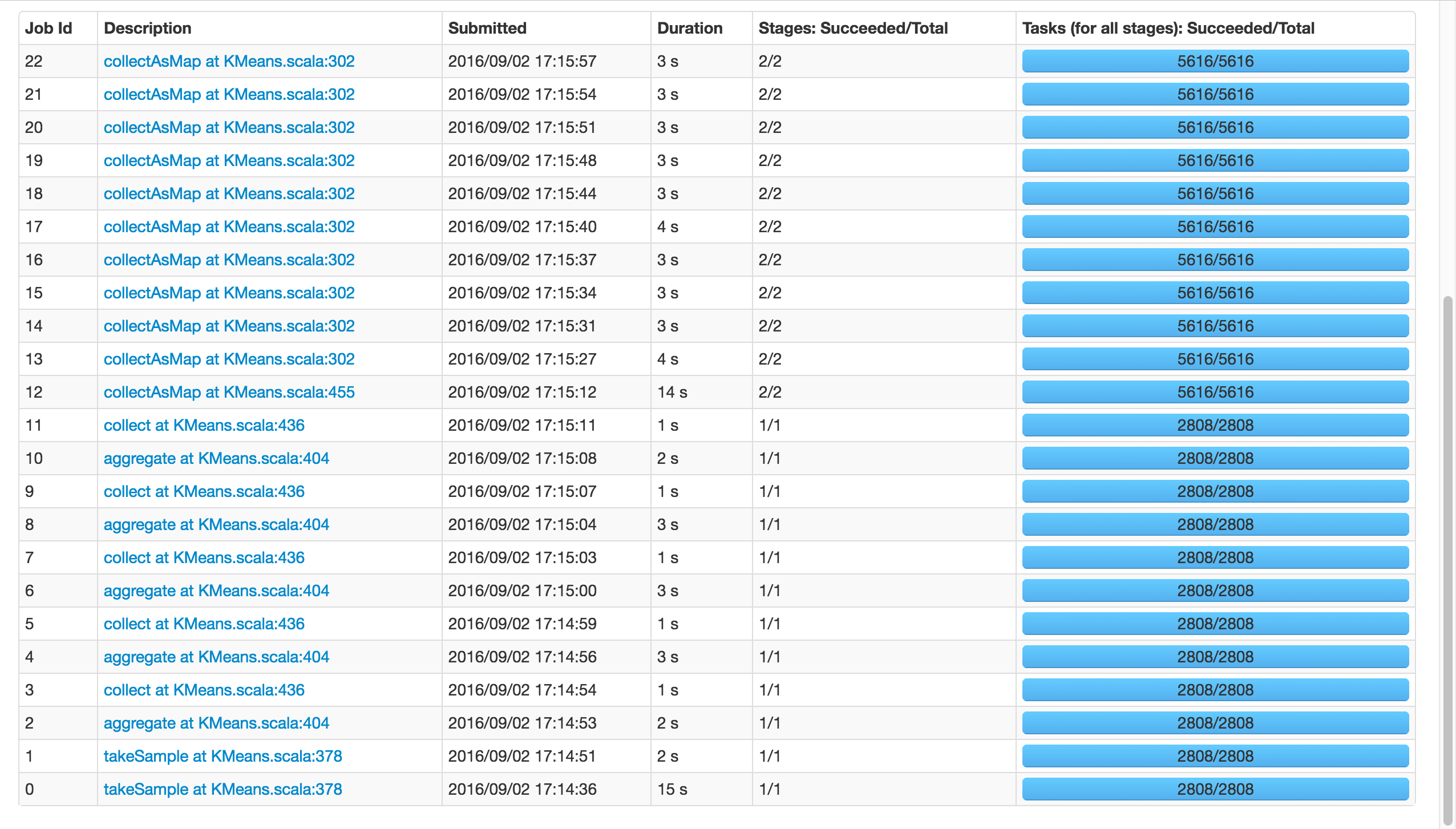
Обратите внимание, что два вызоваtakeSample(), не должно быть проблемой, поскольку в случайной инициализации были вызваны дважды.
Итак, что происходит? Является ли Spark's Kmeansневозможно масштабировать? Кто-нибудь знает? Вы можете воспроизвести?
Если это была проблема с памятью,Я получил бы предупреждения и ошибки, как я был раньше.
Примечание: комментарии Placeybordeaux основаны на выполнении задания врежим клиентагде конфигурации драйвера недействительны, вызывая код выхода 143 и тому подобное (см. историю изменений), а не в режиме кластера, где естьнет сообщений об ошибках, приложениепросто висит.
С нуля 323:Почему алгоритм Spark Mllib KMeans чрезвычайно медленный? связан, но я думаю, что он наблюдает некоторый прогресс, в то время как мой зависает, я оставил комментарий ...
