векторизованная сортировка radix с помощью numpy - может ли она превзойти np.sort?
Numpy нееще иметь сортировку по основанию, поэтому я задавался вопросом, можно ли было написать такую, используя уже существующие функции numpy. Пока что у меня есть следующее, которое работает, но примерно в 10 раз медленнее, чем быстрая сортировка numpy.
Тест и тест:
a = np.random.randint(0, 1e8, 1e6)
assert(np.all(radix_sort(a) == np.sort(a)))
%timeit np.sort(a)
%timeit radix_sort(a)
mask_b цикл может быть по крайней мере частично векторизован, передавая через маски от&и используяcumsum сaxis arg, но это в конечном итоге является пессимизацией, вероятно, из-за увеличенного объема памяти.
Если бы кто-нибудь мог найти способ улучшить то, что у меня есть, мне было бы интересно услышать, даже если это все еще медленнее, чемnp.sort... это скорее случай интеллектуального любопытства и интереса к уловкам.
Обратите внимание, что выможет реализовать быстрая сортировка по счету достаточно легкая, хотя это актуально только для небольших целочисленных данных.
Изменить 1: принятиеnp.arange(n) немного помогает, но это не очень интересно.
Изменить 2: cumsum был на самом деле избыточным (ооо!), но эта более простая версия лишь незначительно помогает с производительностью ..
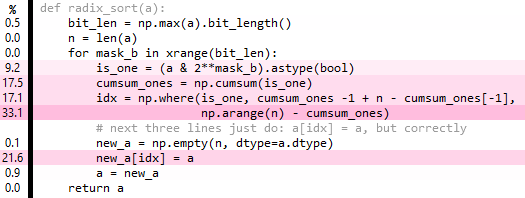
def radix_sort(a):
bit_len = np.max(a).bit_length()
n = len(a)
cached_arange = arange(n)
idx = np.empty(n, dtype=int) # fully overwritten each iteration
for mask_b in xrange(bit_len):
is_one = (a & 2**mask_b).astype(bool)
n_ones = np.sum(is_one)
n_zeros = n-n_ones
idx[~is_one] = cached_arange[:n_zeros]
idx[is_one] = cached_arange[:n_ones] + n_zeros
# next three lines just do: a[idx] = a, but correctly
new_a = np.empty(n, dtype=a.dtype)
new_a[idx] = a
a = new_a
return a
Изменить 3: вместо того, чтобы зацикливаться на отдельных битах, вы можете зацикливаться на двух или более разах, если вы создаете idx в несколько шагов. Использование 2 битов немного помогает, я не пробовал больше:
idx[is_zero] = np.arange(n_zeros)
idx[is_one] = np.arange(n_ones)
idx[is_two] = np.arange(n_twos)
idx[is_three] = np.arange(n_threes)
Редактирует 4 и 5: переход на 4 бита кажется лучшим для ввода, который я тестирую. Также вы можете избавиться отidx шаг целиком Теперь только примерно в 5 раз, а не в 10 раз медленнее, чемnp.sort (источник доступен как суть):
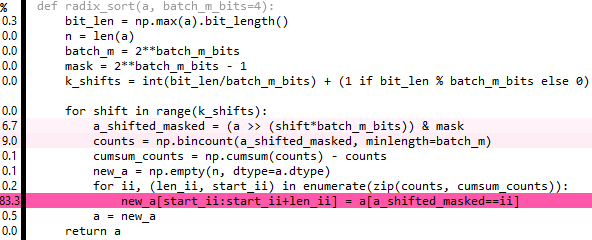
Изменить 6: Это приведенная в порядок версия выше, но это также немногопомедленнее, 80% времени тратится наrepeat а такжеextract - если бы был способ транслироватьextract :( ...
def radix_sort(a, batch_m_bits=3):
bit_len = np.max(a).bit_length()
batch_m = 2**batch_m_bits
mask = 2**batch_m_bits - 1
val_set = np.arange(batch_m, dtype=a.dtype)[:, nax] # nax = np.newaxis
for _ in range((bit_len-1)//batch_m_bits + 1): # ceil-division
a = np.extract((a & mask)[nax, :] == val_set,
np.repeat(a[nax, :], batch_m, axis=0))
val_set <<= batch_m_bits
mask <<= batch_m_bits
return a
Редактирует 7 и 8: На самом деле, вы можете транслировать выдержку, используяas_strided отnumpy.lib.stride_tricks, но это, похоже, не очень помогает в плане производительности:
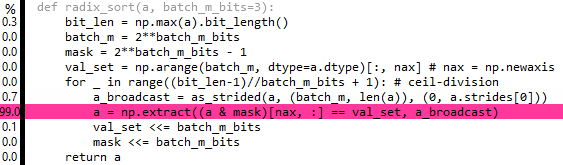
Первоначально это имело смысл для меня на том основании, чтоextract будет перебирать весь массивbatch_m раз, поэтому общее количество строк кэша, запрашиваемых ЦП, будет таким же, как и раньше (просто к концу процесса он запрашивает каждую строку кэшаbatch_m раз). тем не мениереальность в том, чтоextract не достаточно умен, чтобы перебирать произвольные ступенчатые массивы, и должен развернуть массив перед началом, то есть повторение в конечном итоге будет выполнено в любом случае. На самом деле, посмотрев на источникextractТеперь я вижу, что лучшее, что мы можем сделать с этим подходом, это:
a = a[np.flatnonzero((a & mask)[nax, :] == val_set) % len(a)]
что немного медленнее, чемextract, Однако еслиlen(a) является степенью двойки, мы можем заменить дорогой мод мод с& (len(a) - 1), который в конечном итоге будет немного быстрее, чемextract версия (сейчас около 4.9xnp.sort заa=randint(0, 1e8, 2**20). Я полагаю, что мы могли бы сделать эту работу для не степеней двух длин путем заполнения нулями, а затем обрезать лишние нули в конце сортировки ... однако это было бы пессимизацией, если длина уже не была близка к степени два.