Изменение порядка элементов матрицы для отражения кластеризации столбцов и строк в naiive python
Я ищу способ выполнить кластеризацию отдельно для строк матрицы, а не для ее столбцов, переупорядочить данные в матрице, чтобы отразить кластеризацию, и собрать их все вместе. Проблема кластеризации легко решаема, как и создание дендрограммы (например, вэтот блог или в"Программирование коллективного интеллекта"). Однако, как изменить порядок данных для меня остается неясным.
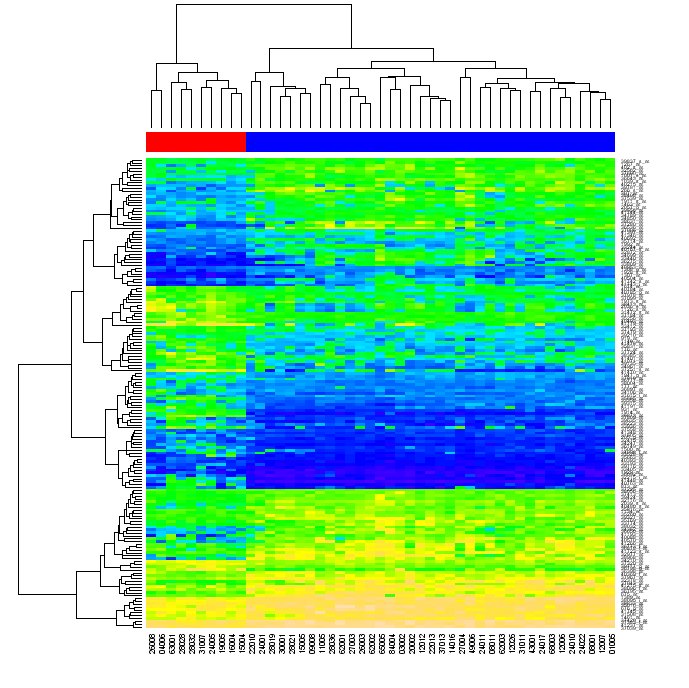
В конце концов, я ищу способ создания графиков, аналогичных приведенному ниже, с использованием наивного Python (с любой «стандартной» библиотекой, такой как numpy, matplotlib и т. Д., Но безиспользуя R или другие внешние инструменты).
{kind=link}
Разъяснения
Меня спросили, что я имел в виду, изменив порядок. Когда вы кластеризуете данные в матрице сначала по строкам матрицы, а затем по ее столбцам, каждая ячейка матрицы может быть идентифицирована по позиции в двух дендрограммах. Если вы переупорядочите строки и столбцы исходной матрицы так, чтобы элементы, расположенные рядом друг с другом в дендрограммах, стали близки друг к другу в матрице, а затем сгенерировали тепловую карту, кластеризация данных может стать очевидной для зрителя (как на рисунке выше)