Метод чтения StreamReader не читает указанное число символов
Я должен разобрать большой файл, так что вместо того, чтобы делать:
string unparsedFile = myStreamReader.ReadToEnd(); // takes 4 seconds
parse(unparsedFile); // takes another 4 seconds
Я хочу воспользоваться преимуществами первых 4 секунд и попытаться сделать обе вещи одновременно, выполнив что-то вроде:
while (true)
{
char[] buffer = new char[1024];
var charsRead = sr.Read(buffer, 0, buffer.Length);
if (charsRead < 1)
break;
if (charsRead != 1024)
{
Console.Write("Here"); // debuger stops here several times why?
}
addChunkToQueue(buffer);
}
вот изображение отладчика :( я добавилint counter чтобы показать на какой итерации мы читаем менее 1024 байта)
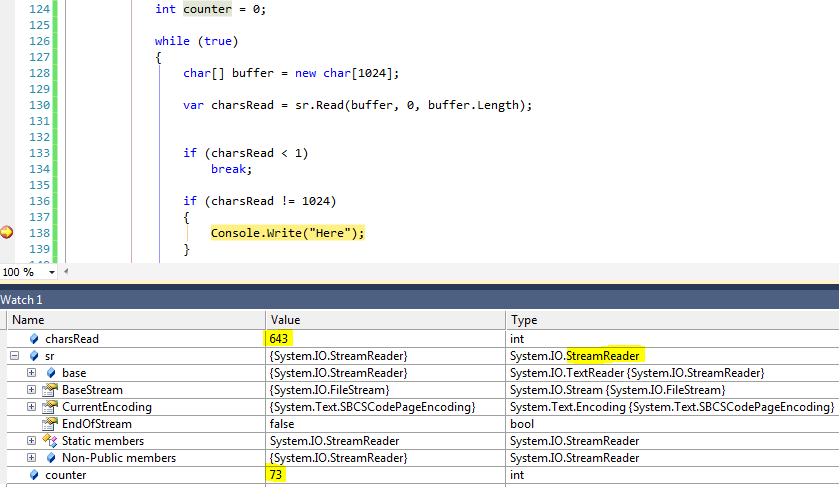
Обратите внимание, что там, где читается 643 символа, а не 1024. На следующей итерации я получаю:
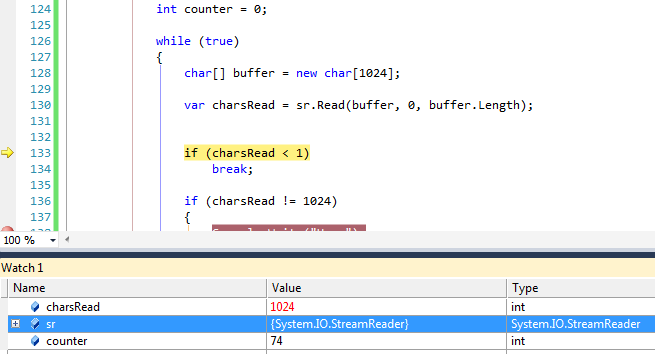
Я думаю, что я должен читать 1024 байта все время, пока не доберусь до последней итерации, где байты запоминания меньше 1024.
So my question is Почему я буду читать "Случайно"? количество символов, как я повторяю бросить цикл while?
EditЯ не знаю, с каким потоком я имею дело. Я выполняю процесс как:
ProcessStartInfo psi = new ProcessStartInfo("someExe.exe")
{
RedirectStandardError = true,
RedirectStandardOutput = true,
UseShellExecute = false,
CreateNoWindow = true,
};
// execute command and return ouput of command
using (var proc = new Process())
{
proc.StartInfo = psi;
proc.Start();
var output = proc.StandardOutput; // <------------- this is where I get the strem
//if (string.IsNullOrEmpty(output))
//output = proc.StandardError.ReadToEnd();
return output;
}
}