'Não foi possível conectar o tempo limite do handshake Net / http: TLS' - Por que o Kubectl não pode se conectar ao servidor Azure Kubernetes? (AKS)
Minha pergunta (para a MS e qualquer outra pessoa) é: Por que esse problema está ocorrendo e qual solução alternativa pode ser implementada pelos próprios usuários / clientes, em oposição ao Suporte da Microsoft?
Obviamente, houve "algumas" outras perguntas sobre esse problema:
Erro de conexão gerenciada do Kubernetes do AzureNão é possível entrar em contato com o tempo limite do handshake do Azure-AKS kube - TLSKubernetes do Azure: tempo limite do handshake TLS (este tem alguns comentários da Microsoft)E vários problemas do GitHub publicados no repositório da AKS:
https://github.com/Azure/AKS/issues/112https://github.com/Azure/AKS/issues/124https://github.com/Azure/AKS/issues/164https://github.com/Azure/AKS/issues/177https://github.com/Azure/AKS/issues/324Além de alguns tópicos do twitter:
https://twitter.com/ternel/status/955871839305261057TL; DRVá para as soluções alternativas nas respostas abaixo.
A melhor solução atual é postar um tíquete de ajuda - e aguardar - ou recriar seu cluster AKS (talvez mais de uma vez, cruze os dedos, veja abaixo ...), mas deve haver algo melhor.Pelo menos, conceda a capacidade de permitir que a AKS visualize clientes, independentemente da camada de suporte, atualize a gravidade da solicitação de suporte para ESTE problema específico.
Você também pode tentar dimensionar seu cluster (supondo que isso não interrompa seu aplicativo).
E o GitHub?Muitos dos problemas acima do GitHub foram fechados como resolvidos, mas o problema persiste. Anteriormente, havia um documento de anúncios referente ao problema, mas nenhuma atualização de status está disponível no momento, mesmo que o problema continue se apresentando:
https://github.com/Azure/AKS/tree/master/annoucementsEstou publicando isso, pois tenho alguns boatos novos que não vi em outros lugares e estou me perguntando se alguém tem ideias sobre outras opções possíveis para solucionar o problema.
Uso de recursos de VM / nó afetadoA primeira parte que não vi mencionada em outro lugar é o uso de recursos nos nós / vms / instâncias que estão sendo afetados pelo problema do Kubectl 'Não foi possível conectar-se ao servidor: net / http: TLS handshake timeout' acima.
Utilização do nó de produçãoOs nós no meu cluster impactado são assim:
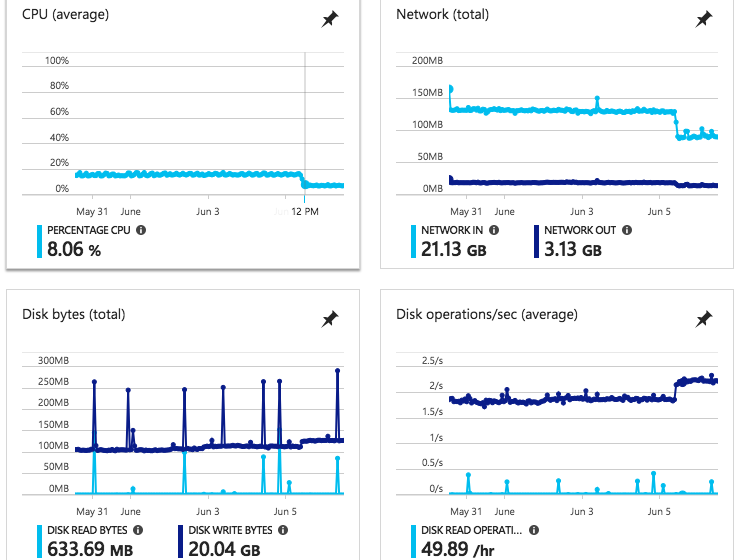
A queda na utilização e na rede io está fortemente correlacionada com o aumento na utilização do disco E com o período em que começamos a enfrentar o problema.
A utilização geral do Nó / VM é geralmente estável antes deste gráfico nos últimos 30 dias, com alguns bumps relacionados ao tráfego do site de produção / atualizações, etc.
Métricas após mitigação de problemas(Adicionado Postmortem)Para o ponto acima, aqui estão as métricas do mesmo nó após aumentar e diminuir o tamanho (o que aliviou nosso problema, mas nem sempre funciona - veja as respostas na parte inferior):
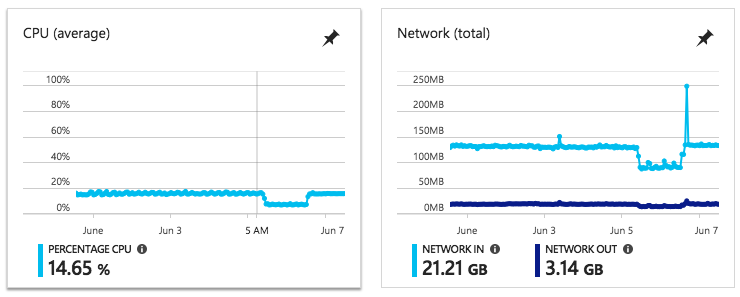
Observe o 'Dip' na CPU e na rede? Foi aí que o problema Net / http: TLS nos afetou - e quando o Servidor AKS estava inacessível no Kubectl. Parece que ele não estava conversando com a VM / Nó, além de não responder às nossas solicitações.
Assim que voltamos (aumentamos os # nós em um e diminuímos - veja as respostas para a solução alternativa), o Metrics (CPU etc) voltou ao normal - e pudemos nos conectar a partir do Kubectl. Isso significa que provavelmente podemos criar um alarme desse comportamento (e eu tenho um problema ao perguntar sobre isso no lado do DevOps do Azure:https://github.com/Azure/AKS/issues/416)
O tamanho do nó afeta potencialmente a frequência de emissãoZimmergren no GitHub indica que ele tem menos problemas com instâncias maiores do que executando nós menores de ossos nus. Isso faz sentido para mim e pode indicar que a maneira como os servidores AKS dividem a carga de trabalho (consulte a próxima seção) pode se basear no tamanho das instâncias.
"O tamanho dos nós (por exemplo, D2, A4, etc) :) Eu experimentei que, ao executar A4 e acima, meu cluster é mais eficiente do que se estivesse executando A2, por exemplo. (E eu tenho mais de uma dúzia similar experiências com combinações de tamanhos e falhas de cluster, infelizmente) ". (https://github.com/Azure/AKS/issues/268#issuecomment-375715435)
Outras referências de impacto de tamanho de cluster:
giorgitado (https://github.com/Azure/AKS/issues/268#issuecomment-376390692)Um servidor AKS responsável por Clusters menores pode ser atingido com mais frequência?
Existência de vários 'servidores' de gerenciamento da AKS em uma região AzA próxima coisa que não vi mencionada em outro lugar é o fato de que você pode ter vários Clusters rodando lado a lado na mesma região em que um Cluster (produção para nós neste caso) é atingido com 'net / http: TLS handshake timeout' e o outro está funcionando bem e pode ser conectado normalmente via Kubectl (para nós, esse é o nosso ambiente de armazenamento idêntico).
O fato de os usuários (Zimmergren, etc. acima) parecerem que o tamanho do nó afeta a probabilidade de esse problema causar impacto também parece indicar que o tamanho do nó pode estar relacionado à maneira como as responsabilidades da sub-região são atribuídas ao AKS sub-regional servidores de gerenciamento.
Isso poderia significar que recriar seu cluster com um tamanho de cluster diferente seria mais provável para colocá-lo em um servidor de gerenciamento diferente - aliviando o problema e reduzindo a probabilidade de que várias recriações fossem necessárias.
Utilização de Cluster de PreparaçãoAmbos os clusters da AKS estão no leste dos EUA. Como referência às métricas de Cluster de 'Produção' acima, nossa utilização de recursos do Cluster de 'Teste' (também leste dos EUA) não tem uma queda maciça na CPU / Rede IO - E não tem o aumento de disco etc. no mesmo período:
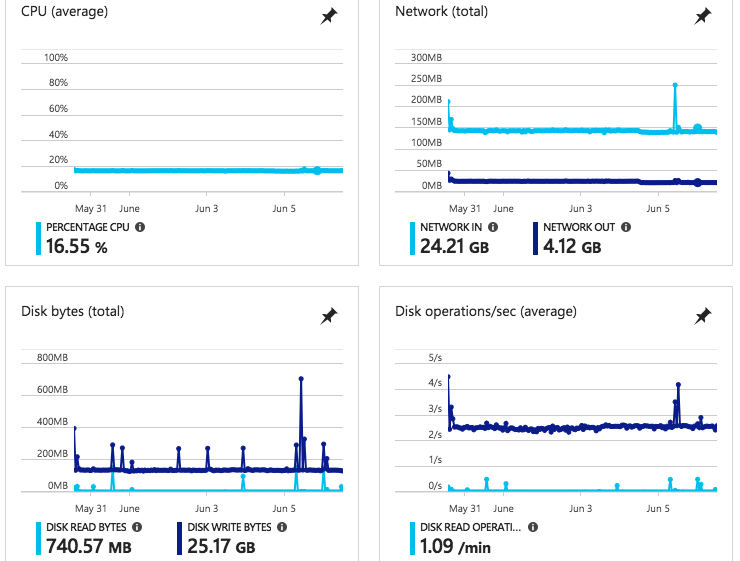
Ambos os nossos Clusters estão executando entradas, serviços, pods, contêineres idênticos, portanto, também é improvável que algo que um usuário esteja fazendo faça com que esse problema surja.
A recriação é apenas algumas vezes bem-sucedidaA existência acima de várias responsabilidades sub-regionais do servidor de gerenciamento da AKS faz sentido com o comportamento descrito por outros usuários no github (https://github.com/Azure/AKS/issues/112), onde alguns usuários podem recriar um cluster (que pode ser contatado), enquanto outros recriam e ainda têm problemas.
Emergência poderia = Múltiplas recriaçõesEm caso de emergência (ou seja, seu local de produção ... como o nosso ... precisa ser gerenciado), você podePROVAVELMENTE apenas recrie até obter um cluster de trabalho que aconteça em uma instância diferente do servidor de gerenciamento da AKS (uma que não seja afetada), mas esteja ciente de que isso pode não acontecer na sua primeira tentativa - a recriação do cluster da AKS não é exatamente instantânea .
Dito isto...
Os recursos nos nós afetados continuam funcionandoTodos os contêineres / entradas / recursos em nossa VM afetada parecem estar funcionando bem e não tenho nenhum alarme disparando para o monitoramento de tempo ativo / recursos (além da estranheza de utilização listada acima nos gráficos)
Quero saber por que esse problema está ocorrendo e qual solução alternativa pode ser implementada pelos próprios usuários, e não pelo Suporte da Microsoft (atualmente há um ticket). Se você tem uma idéia, me avise.
Sugestões potenciais para a causahttps://github.com/Azure/AKS/issues/164#issuecomment-363613110https://github.com/Azure/AKS/issues/164#issuecomment-365389154Por que não GKE?Entendo que o Azure AKS está em pré-visualização e que muitas pessoas se mudaram para o GKE devido a esse problema (). Dito isso, minha experiência com o Azure não foi nada além de positiva até agora e eu preferiria contribuir com uma solução, se possível.
E também ... o GKE ocasionalmente enfrenta algo semelhante:
Tempo limite do handshake TLS com kubernetes no GKEEu estaria interessado em ver se a escala dos nós no GKE também resolveu o problema por lá.