Причина была в тайм-аутах в очереди сообщений.
опрос (к MS и всем остальным): почему возникает эта проблема и какие обходные пути могут быть реализованы самими пользователями / клиентами, а не службой поддержки Microsoft?
Очевидно, было еще несколько вопросов по этому вопросу:
Ошибка управляемого Azure KubernetesНе удается связаться с нашим кубом Azure-AKS - Тайм-аут рукопожатия TLSAzure Kubernetes: тайм-аут рукопожатия TLS (у этого есть некоторая обратная связь Microsoft)И несколько вопросов GitHub, опубликованных в репо AKS:
https://github.com/Azure/AKS/issues/112https://github.com/Azure/AKS/issues/124https://github.com/Azure/AKS/issues/164https://github.com/Azure/AKS/issues/177https://github.com/Azure/AKS/issues/324Плюс несколько тем в твиттере:
https://twitter.com/ternel/status/955871839305261057TL; DRПерейти к обходным путям в ответах ниже.
В настоящее время лучшим решением является отправка запроса о помощи - и подождите - или воссоздание кластера AKS (возможно, несколько раз, скрестите пальцы, см. Ниже ...), но должно быть что-то лучшее.По крайней мере, предоставьте возможность пользователям AKS для предварительного просмотра, независимо от уровня поддержки, обновить серьезность их запросов на поддержку для ЭТОЙ конкретной проблемы.
Вы также можете попробовать масштабировать свой кластер (при условии, что это не сломает ваше приложение).
Что насчет GitHub?Многие из указанных выше проблем GitHub были закрыты как решенные, но проблема сохраняется. Ранее был документ с объявлениями о проблеме, но в настоящее время такие обновления состояния недоступны, хотя проблема продолжает появляться:
https://github.com/Azure/AKS/tree/master/annoucementsЯ публикую это, поскольку у меня есть несколько новых лакомых кусочков, которых я не видел в других местах, и мне интересно, есть ли у кого-нибудь идеи относительно других возможных вариантов решения этой проблемы.
Затрагиваемое использование ресурсов VM / NodeПервая часть, которую я не видел, упоминавшаяся где-то в другом месте, - это использование ресурсов на узлах / vms / instance, на которые влияет вышеуказанная проблема Kubectl «Невозможно подключиться к серверу: net / http: TLS handshake timeout».
Использование производственного узлаУзлы на моем затронутом кластере выглядят так:
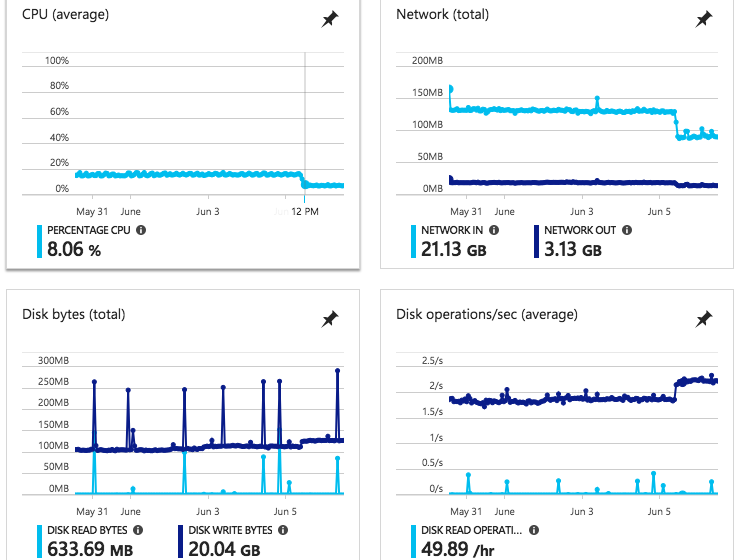
Падение загрузки и сети io сильно коррелирует как с увеличением использования диска, так и с периодом времени, когда мы начали испытывать проблему.
Общее использование узлов / виртуальных машин, как правило, остается неизменным до этой диаграммы в течение предыдущих 30 дней с небольшими изменениями, связанными с трафиком на производственной площадке / обновлениями и т.д.
Метрики после смягчения проблемы(Добавлено после смерти)К вышеупомянутому пункту, вот метрики того же узла после масштабирования вверх, а затем обратно вниз (что, как оказалось, облегчает нашу проблему, но не всегда работает - см. Ответы внизу):
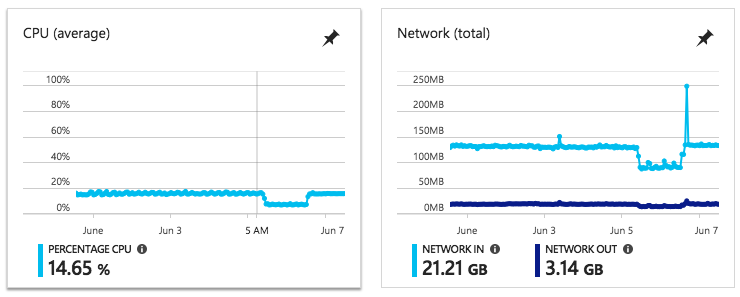
Обратите внимание на «провал» в процессоре и сети? Вот где проблема Net / http: TLS повлияла на нас - и когда сервер AKS был недоступен для Kubectl. Похоже, он не разговаривал с VM / Node в дополнение к тому, что не отвечал на наши запросы.
Как только мы вернулись (масштабировали # узлы вверх на один, а затем вернулись вниз - см. Ответы об обходном пути), показатели (ЦП и т. Д.) Вернулись в нормальное состояние - и мы смогли подключиться из Kubectl. Это означает, что мы, вероятно, можем создать сигнал тревоги для этого поведения (и у меня есть проблема, спрашивая об этом на стороне DevOps Azure:https://github.com/Azure/AKS/issues/416)
Размер узла потенциально влияет на частоту выпускаЦиммергрен на GitHub указывает, что у него меньше проблем с большими экземплярами, чем с пустыми узлами меньших узлов. Это имеет смысл для меня и может указывать, что способ, которым серверы AKS разделяют рабочую нагрузку (см. Следующий раздел), может быть основан на размере экземпляров.
«Размер узлов (например, D2, A4 и т. Д.) :) Я обнаружил, что при запуске A4 и выше мой кластер оказывается здоровее, чем при запуске A2, например. (И у меня более десятка подобных опыт работы с комбинациями размеров и сбоями кластеров, к сожалению). " (https://github.com/Azure/AKS/issues/268#issuecomment-375715435)
Другие ссылки на размер кластера:
Giorgited (https://github.com/Azure/AKS/issues/268#issuecomment-376390692)Может ли сервер AKS, отвечающий за более мелкие кластеры, попадать чаще?
Наличие нескольких серверов AKS Management в одном регионе AzСледующее, что я не видел, упомянутое в другом месте, это тот факт, что вы можете иметь несколько кластеров, работающих бок о бок в одном и том же регионе, где один кластер (производство для нас в этом случае) получает «net / http: TLS handshake timeout» а другой работает нормально и может быть нормально подключен через Kubectl (для нас это наша идентичная промежуточная среда).
Тот факт, что пользователи (Zimmergren и т. Д. Выше), кажется, считают, что размер узла влияет на вероятность того, что эта проблема повлияет, вы также указываете на то, что размер узла может относиться к тому, как обязанности субрегиона назначаются субрегиональному AKS. серверы управления.
Это может означать, что повторное создание кластера с другим размером кластера с большей вероятностью поместит вас на другой сервер управления, что облегчит проблему и уменьшит вероятность того, что потребуется многократное повторное создание.
Использование промежуточного кластераОба наших кластера AKS находятся на востоке США. В качестве ссылки на приведенные выше метрики «производственного» кластера, использование ресурсов нашего «промежуточного» кластера (также в восточной части США) не приводит к значительному падению ввода-вывода ЦП / сети - И не имеет увеличения диска и т. Д. За тот же период:
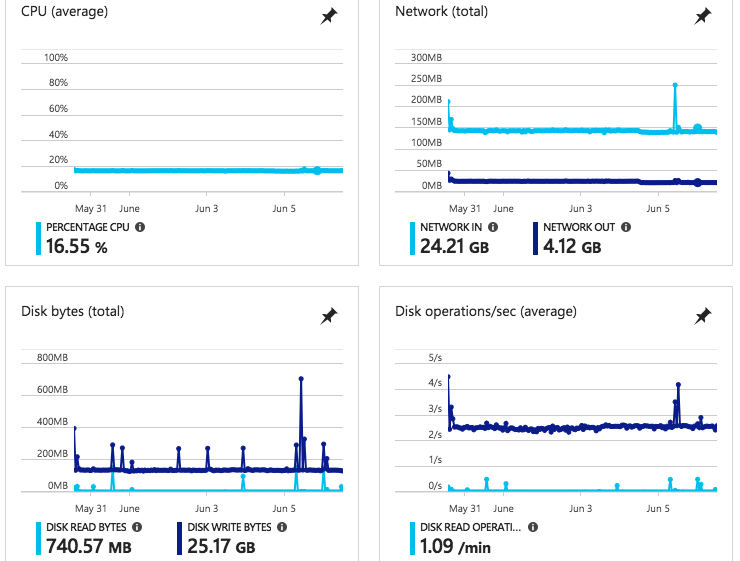
Оба наших кластера работают с одинаковыми входами, службами, модулями и контейнерами, поэтому маловероятно, что что-то, что делает пользователь, вызывает эту проблему.
Пересоздание только ИНОГДА успешноВышеупомянутое существование нескольких субрегиональных обязанностей сервера управления AKS имеет смысл с поведением, описанным другими пользователями на github (https://github.com/Azure/AKS/issues/112) где некоторые пользователи могут воссоздать кластер (с которым можно связаться), в то время как другие воссоздают и все еще имеют проблемы.
Чрезвычайная ситуация может = многократное воссозданиеВ чрезвычайной ситуации (т. Е. Ваш производственный участок ... как наш ... необходимо управлять) вы можетеВЕРОЯТНО просто создайте заново, пока не получите рабочий кластер, который случайно окажется на другом экземпляре сервера управления AKS (который не подвержен влиянию), но помните, что это может не произойти с первой попытки - повторное создание кластера AKS происходит не совсем мгновенно ,
Это сказал ...
Ресурсы на затронутых узлах продолжают функционироватьВсе контейнеры / входы / ресурсы на нашей затронутой виртуальной машине, кажется, работают хорошо, и у меня нет никаких сигналов тревоги для мониторинга времени безотказной работы / ресурсов (кроме странности использования, указанной выше на графиках)
Я хочу знать, почему возникает эта проблема, и какие обходные пути могут быть реализованы самими пользователями, а не службой поддержки Microsoft (в настоящее время есть билет). Если у вас есть идея, дайте мне знать.
Потенциальные намеки на причинуhttps://github.com/Azure/AKS/issues/164#issuecomment-363613110https://github.com/Azure/AKS/issues/164#issuecomment-365389154Почему нет ГКЕ?Я понимаю, что Azure AKS находится в предварительном просмотре и что многие люди перешли в GKE из-за этой проблемы (). Тем не менее, мой опыт работы с Azure до сих пор был только положительным, и я предпочел бы предложить решение, если это вообще возможно.
А также ... GKE иногда сталкивается с чем-то похожим:
Тайм-аут рукопожатия TLS с kubernetes в GKEМне было бы интересно посмотреть, решило ли проблему масштабирование узлов в GKE.