Padrão de Design da Lista de Adjacência do DynamoDB M-M
Referindo-se ahttps://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-adjacency-graphs.html. Fiquei me perguntando se alguém poderia me ajudar.
A primeira imagem é da tabela e a segunda é o GSI. Aqui está a tabela:

Em cima da mesa, não entendo como se deve criar a chave de classificação? Esse é um atributo que armazena o ID da fatura e o ID da fatura? ou dois atributos separados? Sinto que esse é um atributo flexível e, em caso afirmativo, como você diferencia um dos outros? E como devemos construir a consulta na chave de classificação?
É apenas olhando o prefixo "Bill-" ou "Invoice-"? A prática do DynamoDB parece fazer uso de traços ("-") para separar valores em um atributo. Se alguém puder me dar casos de uso de tais coisas, eu também ficaria grato, mas estou saindo tangente, a menos que seja importante neste caso.
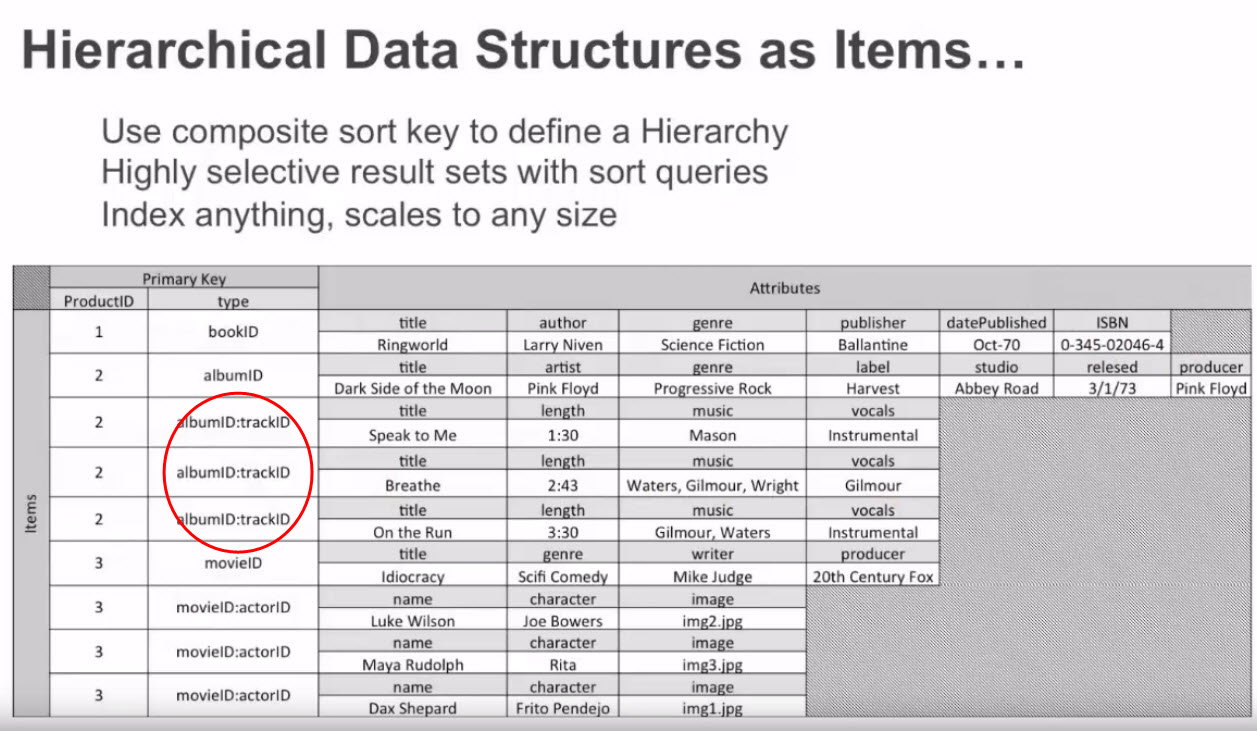
Agora, isso é muito relacionável e muito interessantehttps://youtu.be/xV-As-sYKyg?t=1897, onde o apresentador usa UMA tabela de produtos para armazenar vários tipos de itens: Livros, Álbuns de músicas e Filmes; e cada um tem seus próprios atributos.
Novamente, tenho um problema para entender a chave de classificação usada lá. Entendo que productID = 1 é bookID e productID = 2 é um álbum. Agora, onde fica confuso agora é o que circulei em vermelho. Essas são as faixas do Álbum 2. No entanto, a estrutura da chave de classificação é "albumID: trackID". Agora, onde está o "trackID"? Pretende substituir a palavra "trackID" pela identificação real? ou é para ser um texto exatamente como "albumID: trackID" ?.
E se eu quisesse consultar um trackID específico? qual seria a sintaxe da minha consulta?
Por favor, veja a imagem aqui do youtube:
Obrigado a todos antecipadamente !!! :-)