Como devo interpretar esses resultados do VTune?
Estou tentando paralelamenteesta código usando o OpenMP. O OpenCV (construído usando IPP para melhor eficiência) é usado como biblioteca externa.
Estou tendo problemas de uso desequilibrado da CPU emparallel fors, mas parece que não há desequilíbrio de carga. Como você verá, isso pode ser devido aKMP_BLOCKTIME=0, mas isso pode ser necessário devido a bibliotecas externas (IPP, TBB, OpenMP, OpenCV). Nas demais perguntas, você encontrará mais detalhes e dados que podem ser baixados.
Estes são os links do Google Drive para meus resultados do VTune:
c755823 KMP_BLOCKTIME básico = 0 30 execuções : ponto de acesso básico com a variável de ambiente KMP_BLOCKTIME configurada como 0 em 30 execuções da mesma entrada
c755823 básico 30 execuções : o mesmo que acima, mas com o padrão KMP_BLOCKTIME = 200
c755823 avançado KMP_BLOCKTIME = 0 30 execuções : igual ao primeiro, mas hotspot avançado
Para quem estiver interessado, posso enviar o código original de alguma forma.
No meu Intel i7-4700MQ, o tempo real do relógio de parede do aplicativo, em média, em 10 execuções, é de cerca de 0,73 segundos. Eu compilo o código comicpc 2017 atualização 3 com os seguintes sinalizadores do compilador:
INTEL_OPT=-O3 -ipo -simd -xCORE-AVX2 -parallel -qopenmp -fargument-noalias -ansi-alias -no-prec-div -fp-model fast=2 -fma -align -finline-functions
INTEL_PROFILE=-g -qopt-report=5 -Bdynamic -shared-intel -debug inline-debug-info -qopenmp-link dynamic -parallel-source-info=2 -ldl
Além disso, eu definoKMP_BLOCKTIME=0 porque o valor padrão (200) estava gerando uma enorme sobrecarga.
Podemos dividir o código em 3 regiões paralelas (agrupadas em apenas uma#pragma parallel para eficiência) e um serial anterior, que representa cerca de 25% do algoritmo (e não pode ser paralelo).
Vou tentar descrevê-los (ou você pode pular diretamente para a estrutura de código):
Nós criamos umparallel região para evitar a sobrecarga para criar uma nova região paralela. O resultado final é preencher as linhas de um objeto de matriz,cv::Mat descriptor. Temos 3 compartilhadostd::vector objetos:blurs que é uma cadeia de borrões (não paralelamente) usandoGuassianBlur pelo OpenCV (que usa a implementação IPP de borrões da guassiana) (b)hessResps (tamanho conhecido, digamos 32) (c)findAffineShapeArgs (tamanho desconhecido, mas na ordem de milhares de elementos, digamos 2,3k) (d)cv::Mat descriptors (tamanho desconhecido, resultado final). Na parte serial, preenchemos `blurs, que é um vetor somente leitura.Na primeira região paralela,hessResps é preenchido usandoblurs sem nenhum mecanismo de sincronização.Na segunda região paralelafindLevelKeypoints é preenchido usandohessResps como somente leitura. Desde afindAffineShapeArgs tamanho é desconhecido, precisamos de um vetor locallocalfindAffineShapeArgs que será anexado afindAffineShapeArgs no próximo passoDesde afindAffineShapeArgs é compartilhado e seu tamanho é desconhecido, precisamos de umcritical seção onde cadalocalfindAffineShapeArgs é anexado a ele.Na terceira região paralela, cadafindAffineShapeArgs é usado para gerar as linhas da finalcv::Mat descriptor. Mais uma vez, desdedescriptors é compartilhado, precisamos de uma versão localcv::Mat localDescriptors.Uma finalcritical seçãopush_back cadalocalDescriptors paradescriptors. Observe que isso é extremamente rápido, poiscv::Mat é "meio" um ponteiro inteligente, então nóspush_back ponteiros.Esta é a estrutura de código:
cv::Mat descriptors;
std::vector<Mat> blurs(blursSize);
std::vector<Mat> hessResps(32);
std::vector<FindAffineShapeArgs> findAffineShapeArgs;//we don't know its tsize in advance
#pragma omp parallel
{
//compute all the hessianResponses
#pragma omp for collapse(2) schedule(dynamic)
for(int i=0; i<levels; i++)
for (int j = 1; j <= scaleCycles; j++)
{
hessResps[/**/] = hessianResponse(/*...*/);
}
std::vector<FindAffineShapeArgs> localfindAffineShapeArgs;
#pragma omp for collapse(2) schedule(dynamic) nowait
for(int i=0; i<levels; i++)
for (int j = 2; j < scaleCycles; j++){
findLevelKeypoints(localfindAffineShapeArgs, hessResps[/*...*], /*...*/); //populate localfindAffineShapeArgs with push_back
}
#pragma omp critical{
findAffineShapeArgs.insert(findAffineShapeArgs.end(), localfindAffineShapeArgs.begin(), localfindAffineShapeArgs.end());
}
#pragma omp barrier
#pragma omp for schedule(dynamic) nowait
for(int i=0; i<findAffineShapeArgs.size(); i++){
{
findAffineShape(findAffineShapeArgs[i]);
}
#pragma omp critical{
for(size_t i=0; i<localRes.size(); i++)
descriptors.push_back(localRes[i].descriptor);
}
}
No final da pergunta, você pode encontrarFindAffineShapeArgs.
Estou usando o Intel Amplifier para ver pontos de acesso e avaliar meu aplicativo.
A análise do OpenMP Potential Gain diz que o ganho potencial, se houver um balanceamento de carga perfeito, seria de 5,8%; portanto, podemos dizer que a carga de trabalho é equilibrada entre diferentes CPUs.
Este é o histograma de uso da CPU para a região OpenMP (lembre-se de que este é o resultado de 10 execuções consecutivas):
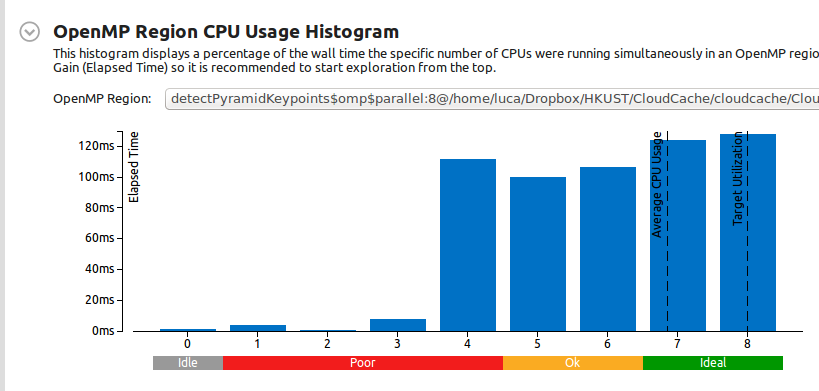
Como você pode ver, o uso médio da CPU é de 7 núcleos, o que é bom.
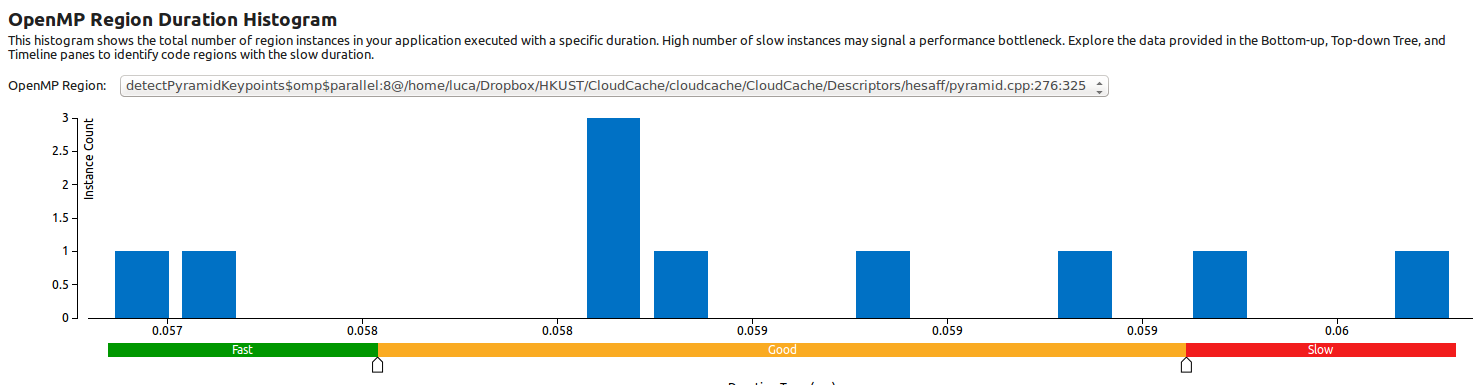
Este histograma de duração da região do OpenMP mostra que nessas 10 execuções a região paralela é executada sempre com o mesmo tempo (com uma propagação em torno de 4 milissegundos):
Esta é a guia Chamador / Destinatário:
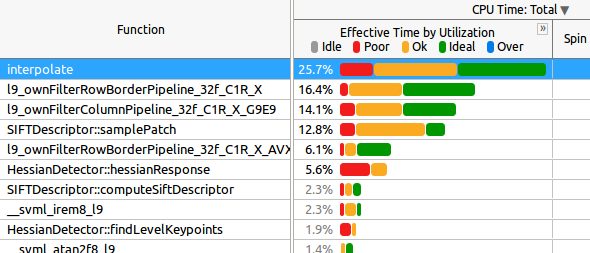
Para seu conhecimento:
interpolate é chamado na última região paralelal9_ownFilter* todas as funções são chamadas na última região paralelasamplePatch é chamado na última região paralela.hessianResponse é chamado na segunda região paralelaAgora meuprimeira pergunta é: como devo interpretar os dados acima? Como você pode ver, em muitas das funções na metade do tempo o "Tempo efetivo por utilização" é "ok", que provavelmente se tornaria "Insatisfatório" com mais núcleos (por exemplo, em uma máquina KNL, onde testarei o aplicação seguinte).
Finalmente, este é o resultado da análise Wait and Lock:
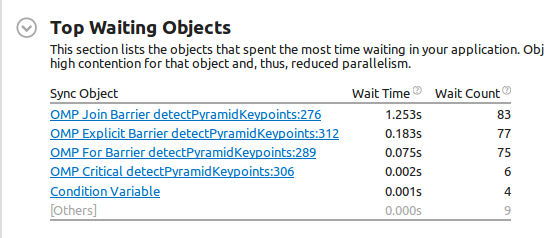
Agora, esta é a primeira coisa estranha: linha276 Join Barrier (que corresponde ao objeto de espera mais caro)) is#pragma omp parallel`, portanto, o início da região paralela. Parece que alguém gerou tópicos antes. Estou errado? Além disso, o tempo de espera é maior que o próprio programa (0,827s vs 1,253s da Join Barrier que estou falando)! Mas talvez isso se refira à espera de todos os threads (e não ao tempo do relógio de parede, o que é claramente impossível, pois é mais longo que o próprio programa).
Em seguida, a barreira explícita na linha 312 é#pragma omp barrier do código acima e sua duração é de 0,183s.
Olhando para a guia Chamador / Destinatário:
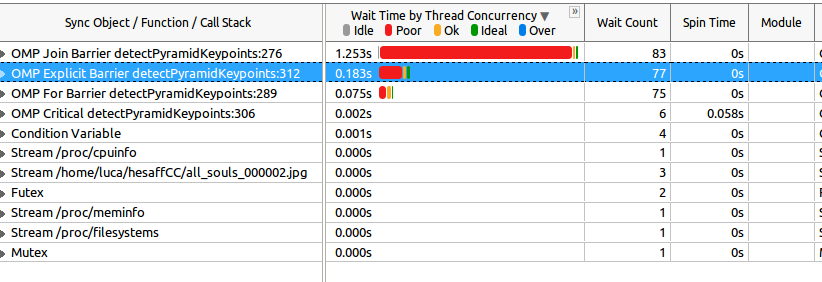
Como você pode ver, a maior parte do tempo de espera é ruim, portanto se refere a um thread. Mas tenho certeza de que estou entendendo isso.Minha segunda pergunta é: podemos interpretar isso como "todos os threads aguardam apenas um thread que fica para trás?".
FindAffineShapeArgs definição:
struct FindAffineShapeArgs
{
FindAffineShapeArgs(float x, float y, float s, float pixelDistance, float type, float response, const Wrapper &wrapper) :
x(x), y(y), s(s), pixelDistance(pixelDistance), type(type), response(response), wrapper(std::cref(wrapper)) {}
float x, y, s;
float pixelDistance, type, response;
std::reference_wrapper<Wrapper const> wrapper;
};
As 5 principais regiões paralelas por ganho potencial na exibição de resumo mostram apenas uma região (a única)

Veja o agrupamento "/ OpenMP Region / OpenMP Barreira a barreira", esta é a ordem dos loops mais caros:
O 3º loop:
pragma omp para agendamento (dinâmico) agorapara (int i = 0; i
é o mais caro (como eu já sabia) e aqui está uma captura de tela da visualização gasta:
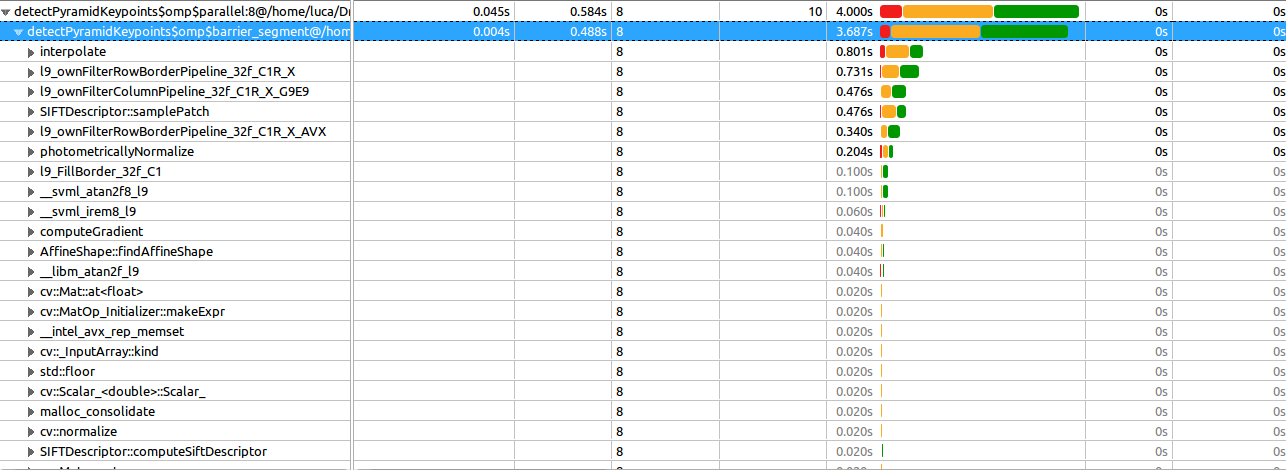
Como você pode ver, muitas funções são do OpenCV, que explora o IPP e é (deveria ser) já otimizado. A expansão das duas outras funções (interpolar e samplePatch) mostra uma [Nenhuma informação da pilha de chamadas]. O mesmo para todas as outras funções (também em outras regiões).
A segunda região mais cara é o segundo paralelo para:
#pragma omp for collapse(2) schedule(dynamic) nowait
for(int i=0; i<levels; i++)
for (int j = 2; j < scaleCycles; j++){
findLevelKeypoints(localfindAffineShapeArgs, hessResps[/*...*], /*...*/); //populate localfindAffineShapeArgs with push_back
}
Aqui está a visão expandida:

E finalmente o terceiro mais caro é o primeiro loop:
#pragma omp for collapse(2) schedule(dynamic)
for(int i=0; i<levels; i++)
for (int j = 1; j <= scaleCycles; j++)
{
hessResp,s[/**/] = hessianResponse(/*...*/);
}
Aqui está a exibição gasta:

Se você quiser saber mais, use meus arquivos VTune anexados ou apenas pergunte!