Fluxo de dados da primavera com 2 fontes alimentando um processador / coletor
Estou procurando conselhos sobre como configurar um fluxo do Spring Data Flow para um caso de uso específico.
Meu caso de uso:
Eu tenho 2 RDBMS e preciso comparar os resultados das consultas executadas em cada uma. As consultas devem ser executadas aproximadamente simultaneamente. Com base no resultado da comparação, devo poder enviar um email por meio de um aplicativo de coletor de email personalizado que criei.
Eu imagino o diagrama de fluxo para algo parecido com isto (desculpe pela pintura):
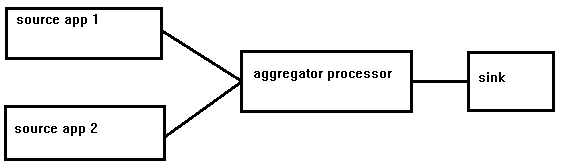
O problema é que, até onde sei, o SDF não permite que um fluxo seja composto com 2 fontes. Parece-me que algo assim deveria ser possível sem forçar demais os limites da estrutura. Estou procurando respostas que forneçam uma boa abordagem para esse cenário enquanto estiver trabalhando na estrutura do SDF.
Estou usando o Kafka como um intermediário de mensagens e o servidor de fluxo de dados está usando o mysql para manter as informações do fluxo.
Eu considerei criar um aplicativo de origem personalizado que controla duas fontes de dados e envia as mensagens no canal de saída. Isso eliminaria meu requisito de 2 fontes, mas parece que exigiria uma quantidade significativa de personalização do aplicativo de origem jdbc.
Desde já, obrigado.