Função len lenta no quadro de dados distribuído dask
Eu tenho testado como usar o dask (cluster com 20 núcleos) e estou surpreso com a velocidade que recebo ao chamar uma função len vs cortar através de loc.
import dask.dataframe as dd
from dask.distributed import Client
client = Client('192.168.1.220:8786')
log = pd.read_csv('800000test', sep='\t')
logd = dd.from_pandas(log,npartitions=20)
#This is the code than runs slowly
#(2.9 seconds whilst I would expect no more than a few hundred millisencods)
print(len(logd))
#Instead this code is actually running almost 20 times faster than pandas
logd.loc[:'Host'].count().compute()
Alguma idéia de por que isso poderia estar acontecendo? Não é importante para mim que o len corra rápido, mas sinto que, ao não entender esse comportamento, há algo que não estou entendendo sobre a biblioteca.
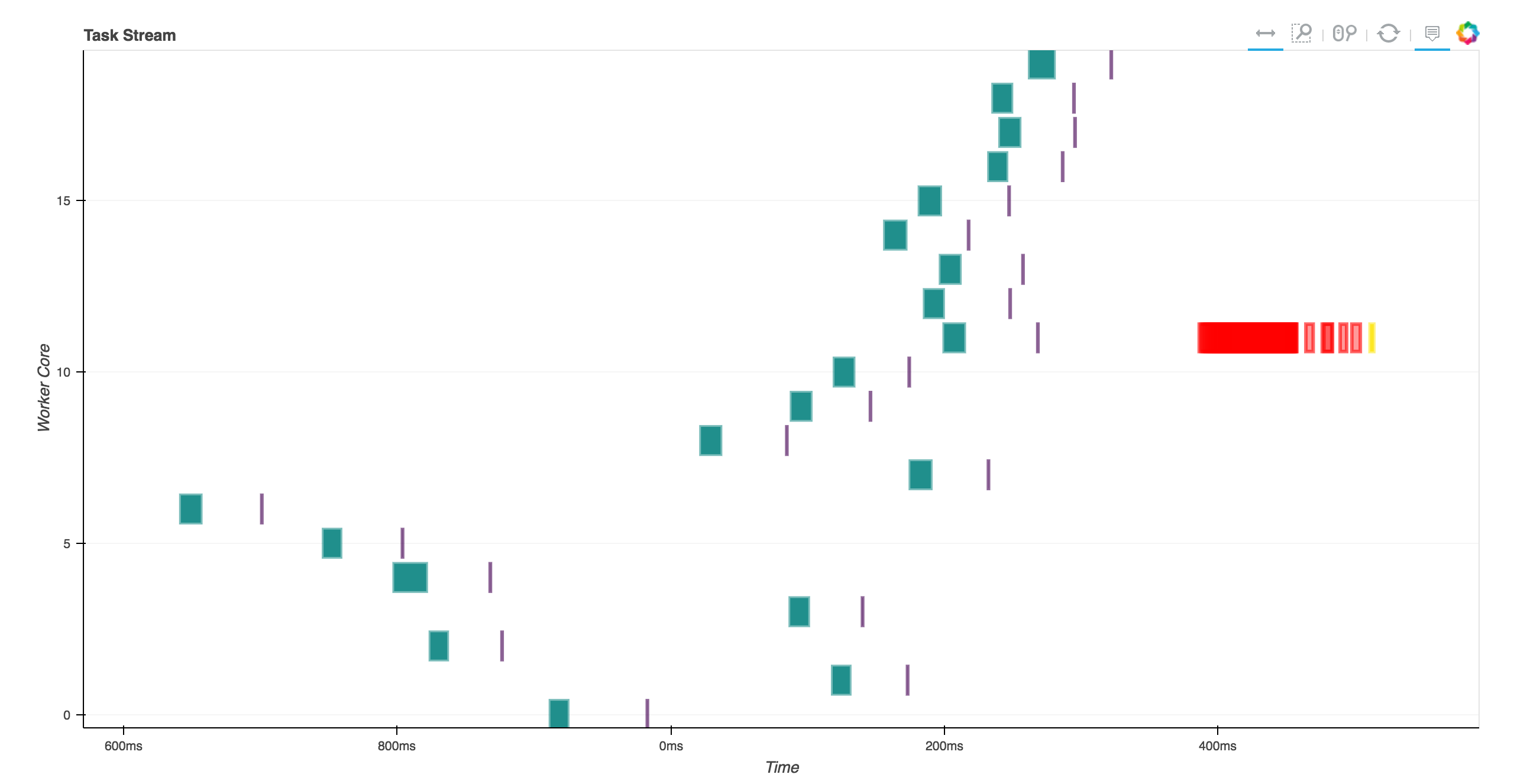
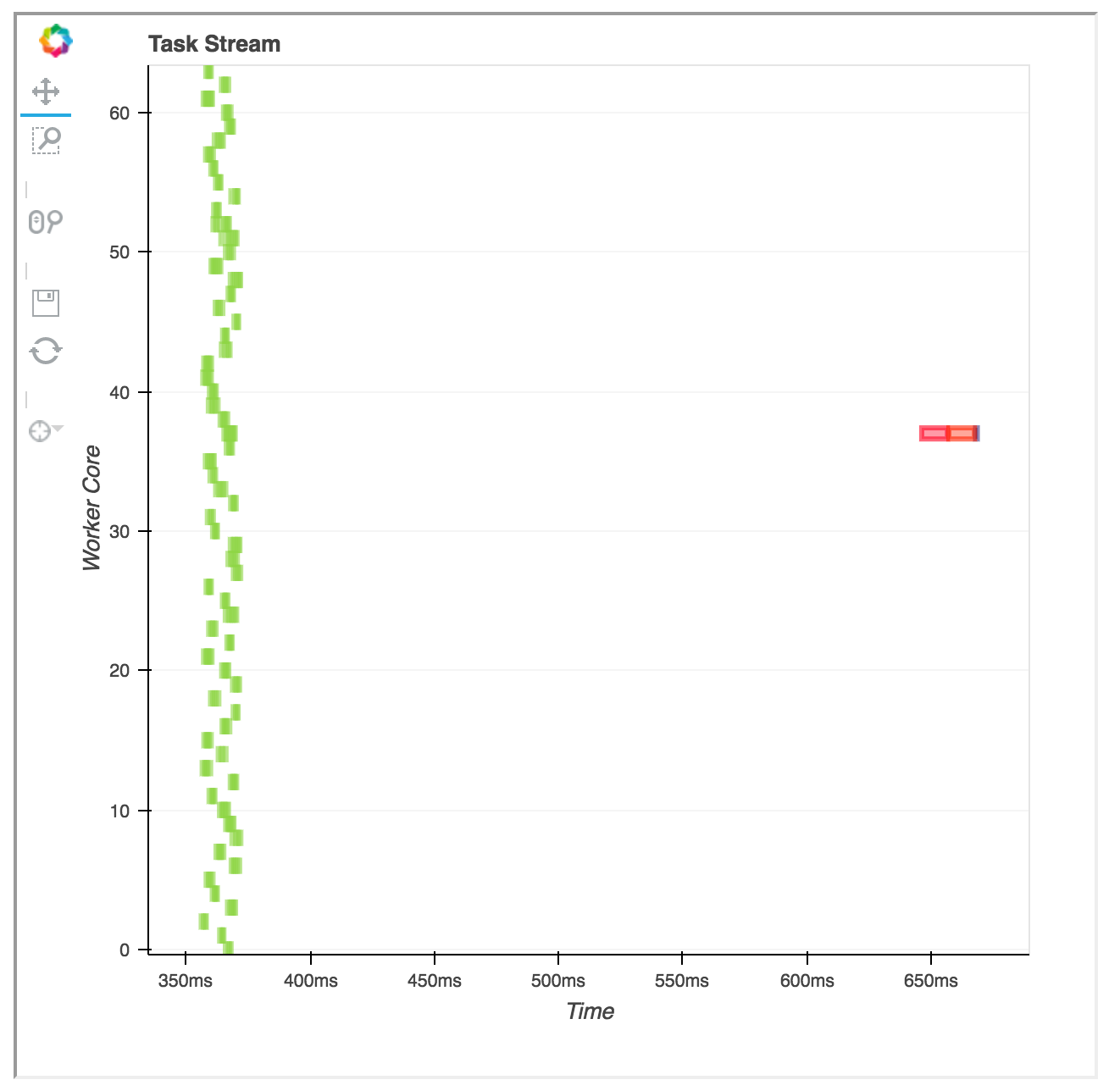
Todas as caixas verdes correspondem a "from_pandas", enquanto neste artigo por Matthew Rocklinhttp://matthewrocklin.com/blog/work/2017/01/12/dask-dataframes o gráfico de chamada fica melhor (len_chunk é chamado, significativamente mais rápido e as chamadas não parecem bloqueadas e esperam que um trabalhador termine sua tarefa antes de iniciar o outro)