Revelar os recursos do cluster dos modos k
Estou realizando uma análise de cluster em dados categóricos, portanto, usando a abordagem dos modos k.
Meus dados têm o formato de uma pesquisa de preferência: como você gosta de cabelos e olhos?
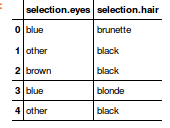{kind=link}
O entrevistado pode obter respostas de um conjunto fixo (de múltipla escolha) de 4 possibilidades.
Portanto, eu obtenho os manequins, aplico os modos k, conecto os clusters de volta ao df inicial e os planto em 2D com pca.
Meu código se parece com:
import numpy as np
import pandas as pd
from kmodes import kmodes
df_dummy = pd.get_dummies(df)
#transform into numpy array
x = df_dummy.reset_index().values
km = kmodes.KModes(n_clusters=3, init='Huang', n_init=5, verbose=0)
clusters = km.fit_predict(x)
df_dummy['clusters'] = clusters
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(2)
# Turn the dummified df into two columns with PCA
plot_columns = pca.fit_transform(df_dummy.ix[:,0:12])
# Plot based on the two dimensions, and shade by cluster label
plt.scatter(x=plot_columns[:,1], y=plot_columns[:,0], c=df_dummy["clusters"], s=30)
plt.show()
e eu posso visualizar:
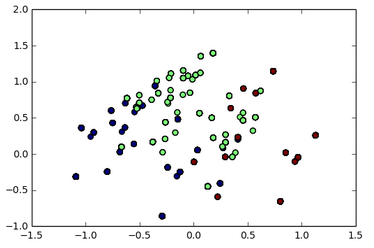{kind=link}
Agora meu problema é:De alguma forma, pode revelar a característica distintiva de cada cluster? ou seja, quais são as principais características (talvez cabelos loiros e olhos azuis) do grupo de pontos verdes no gráfico de dispersão?
Entendo que o cluster aconteceu, mas não consigo encontrar uma maneira de traduzir o que o cluster realmente significa.
Devo jogar com o objeto .labels_?