Revelar características del clúster k-modes
Estoy realizando un análisis de clúster en datos categóricos, por lo tanto, uso el enfoque de modos k.
Mis datos tienen la forma de una encuesta de preferencias: ¿Qué le parece el cabello y los ojos?
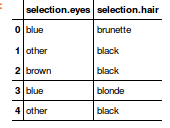{kind=link}
El encuestado puede recoger una respuesta de un conjunto fijo (opción múltiple) de 4 posibilidades.
Por lo tanto, obtengo los dummies, aplico los modos k, vuelvo a unir los grupos al df inicial y luego los trazo en 2D con pca.
Mi código se ve así:
import numpy as np
import pandas as pd
from kmodes import kmodes
df_dummy = pd.get_dummies(df)
#transform into numpy array
x = df_dummy.reset_index().values
km = kmodes.KModes(n_clusters=3, init='Huang', n_init=5, verbose=0)
clusters = km.fit_predict(x)
df_dummy['clusters'] = clusters
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(2)
# Turn the dummified df into two columns with PCA
plot_columns = pca.fit_transform(df_dummy.ix[:,0:12])
# Plot based on the two dimensions, and shade by cluster label
plt.scatter(x=plot_columns[:,1], y=plot_columns[:,0], c=df_dummy["clusters"], s=30)
plt.show()
y puedo visualizar:
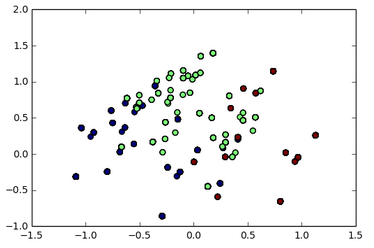{kind=link}
Ahora mi problema es:¿Puede de alguna manera revelar la característica distintiva de cada grupo? es decir, ¿cuáles son las características principales (tal vez cabello rubio y ojos azules) del grupo de puntos verdes en el diagrama de dispersión?
Entiendo que la agrupación ha sucedido, pero no puedo encontrar una manera de traducir lo que realmente significa la agrupación.
¿Debo jugar con el objeto .labels_?